Monado Out of Process流程分析
由于OpenXR的runtime存在in process和out of process两种模式,逆向了oculus quest2的工程以后发现竞品是out of process的方案,然后很多小伙伴都问到了同一个问题,Composite的部分是在哪里做的,所以带着这两个问题来系统学习了一下。
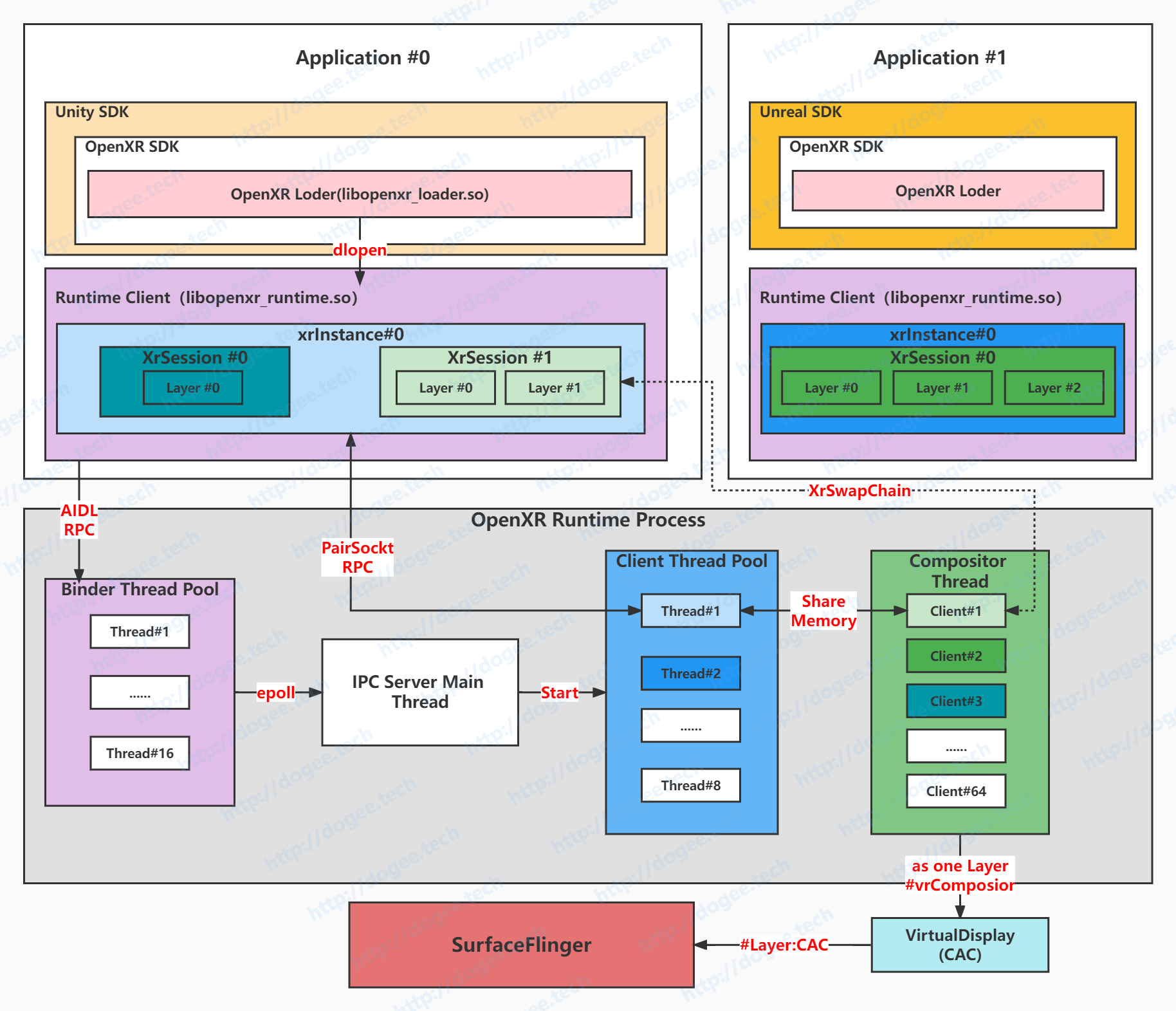
ARCH Picture
TL;DR
这篇内容是一个代码学习笔记,内容比较长,细节部分从源起编译开始,摘录主要的结论如下:
Application和OpenXRRuntime是不同的进程,通过IPC的方式进行通讯。
OpenXRRuntime内部有16+1+8+1条线程:
16:Binder线程,Monado的方案下OpenXRRuntime是一个带有AIDL的Service apk,其中binder线程有16条
1:ipc_server_mainloop线程,主要是监听来自Application进程的AIDL connect事件,并在Runtime进程中创建Client线程
实现的部分参考:Init From AIDL-Client Connected-Thread2:Server Thread
8:Runtime端的Client线程,每一个Application进程在使用OpenXR时,在Runtime进程中都会有一条Client线程与之对应
Monado方案下最多为8条,
#define IPC_MAX_CLIENTS 8
实现的部分参考:Init From AIDL-Client Connected-Thread3:new Client Thread1:Compositor Thread,这里会对所有Client端的SwapChain做Compose。
- Client的MAX NUMBER为64,也就是我们最多可以同时存在64个Session,这个跟之前的8的概念是不一样的
- TODO:Swapchain和Layer的关系,还没有弄清楚,这个需要在后面去看。
这里简单看了一部分,汇总在Compositor-Thread,后面再补
12345678>>> struct multi_system_compositor> {> ......> struct multi_compositor *clients[MULTI_MAX_CLIENTS];> };>
Session的focus是由Runtime进程决定的,全局只会有一个focus状态的Session,但是info为Overlay的session为特殊session,其visible和focuse永远为true,常驻显示应该就是利用的这个特性。
这部分需要写demo验证,并需要重新去看一下spec的定义
双目渲染的部分,OpenXR Helloworld是在应用端做的,分了左右眼,从代码上看在xrEndFrame也有做两次的填充
这部分是否可以在OpenXR暴露出去的SDK层直接做掉,从而对应用开发者无感知?
ATW的部分是在Compositor Thread做的
TODO的部分写在最后了,这里也先罗列一下:
[ X ] swapchain的部分涉及到了ipc_shared_memory的结构体,这部分client进程/Runtime Client线程/Compositor线程三者间的使用关系是怎么样的。
[ X ] session的状态机管理,目前已经知道了IDLE,READY,SYNC,VISIBLE以及FOUCS,还有另外的几个状态是怎么流转的。
这部分会结合OpenXR的helloworld在手机上进行学习验证
源起编译
在monado的代码中,可以通过带入编译参数outOfProcess
|
|
在使用outofProcess的时候会带入一个macro:XRT_FEATURE_SERVICE = ON,最终的交付件为openxr_monado和monado-service,因此在in process之外还会额外编译一个模块monado-service。
monado-service
由于定义了macro:XRT_FEATURE_SERVICE = ON,因此在整个编译的时候,会include到对应的CMakeLists.txt
monado/src/xrt/targets/CMakeLists.txt- 1234567if(XRT_FEATURE_SERVICE AND XRT_FEATURE_OPENXR)if(ANDROID)add_subdirectory(service-lib)else()......endif()endif()
monado/src/xrt/targets/service-lib/CMakeLists.txt- 12345678910111213add_library(monado-service MODULE service_target.cpp)target_link_libraries(monado-servicePRIVATEaux_utilst_proberipc_servercomp_maintarget_liststarget_instancexrt-external-jni-wrap)
Init From AIDL
由于存在了IPC模块,在整个运行上跟in process的模式略微有点区别,但是大的结构上其实并没有什么区别。
详细的介绍可以参考:https://www.khronos.org/registry/OpenXR/specs/1.0/loader.html#android-active-runtime-location
简单来说,Application进程依旧是通过Content Provider的形式查询到对应runtime so所在的存储地址,然后通过dlopen的形式加载对应so库到Application进程的内存空间中。
xrCreateInstance
根据之前的认知,整个调用关系链:
- xrCreateInstance是标准的OpenXR api
- 初始化过程中,IPC相关的有两步
- 使用Android Service机制通过bind-ServiceConnection建立IPC通讯机制
- 使用AIDL进行RPC调用
- Application进程作为Client端,会持有IMonado的local对象
- 初始化过程中,IPC相关的有两步
- 整个过程中比较重要的函数是:
blockingConnect,其中会做两件事:- IMonado.createSurface
- IMonado.connect
整个调用流程图如下:
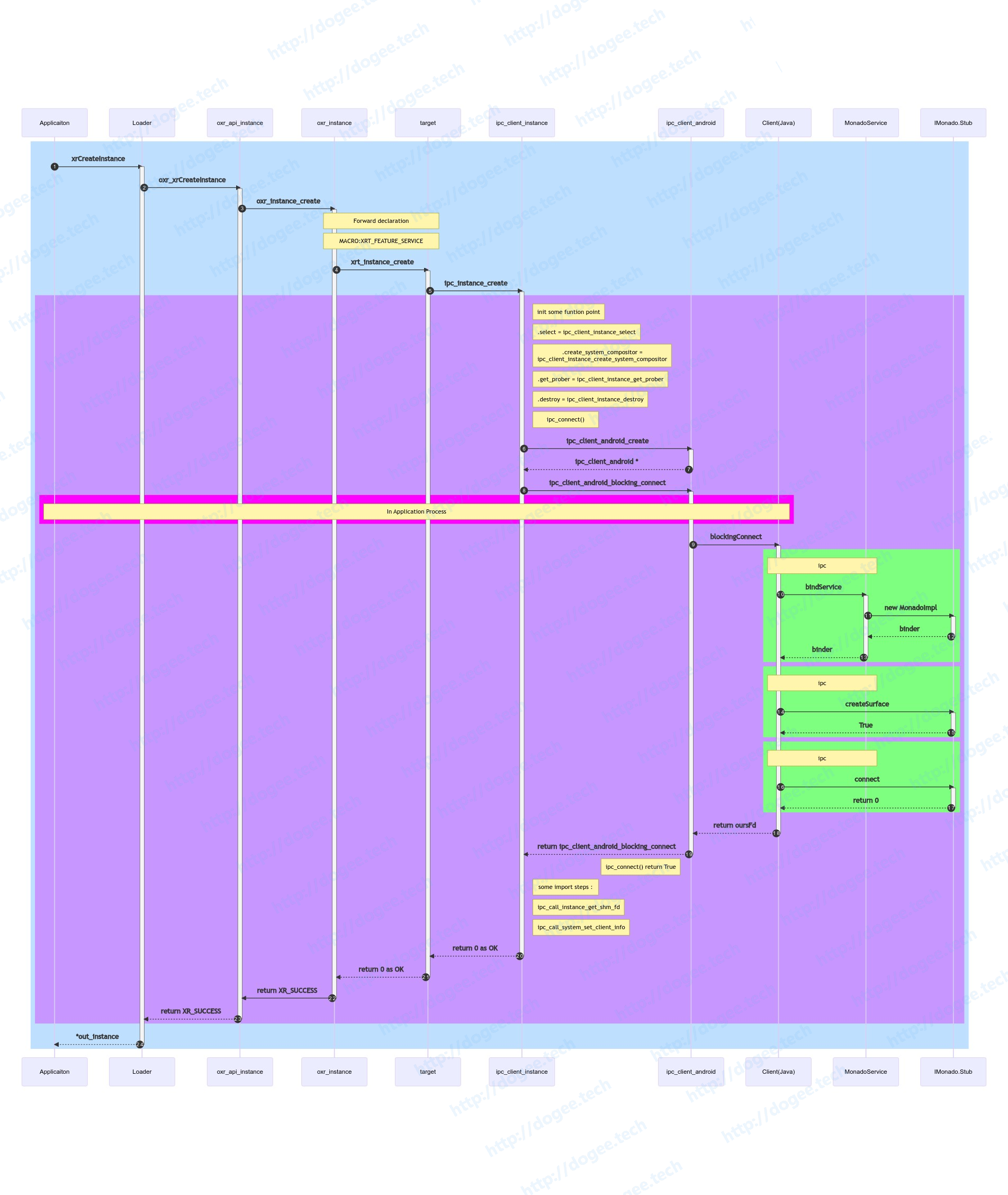
sequenceDiagram autonumber rect rgb(191, 223, 255) Applicaiton ->>+ Loader: xrCreateInstance Loader ->>+ oxr_api_instance: oxr_xrCreateInstance oxr_api_instance ->>+ oxr_instance: oxr_instance_create note over oxr_instance, target: Forward declaration note over oxr_instance, target: MACRO:XRT_FEATURE_SERVICE oxr_instance ->>+ target:xrt_instance_create target ->>+ ipc_client_instance:ipc_instance_create rect rgb(200, 150, 255) note right of ipc_client_instance: init some funtion point note right of ipc_client_instance: .select = ipc_client_instance_select; note right of ipc_client_instance: .create_system_compositor =
ipc_client_instance_create_system_compositor; note right of ipc_client_instance: .get_prober = ipc_client_instance_get_prober; note right of ipc_client_instance: .destroy = ipc_client_instance_destroy; note right of ipc_client_instance: ipc_connect() ipc_client_instance ->>+ ipc_client_android:ipc_client_android_create ipc_client_android -->>- ipc_client_instance:ipc_client_android * ipc_client_instance ->>+ ipc_client_android:ipc_client_android_blocking_connect rect rgb(255, 0, 255) note over Client(Java),Applicaiton: In Application Process end ipc_client_android ->>+ Client(Java):blockingConnect rect rgb(127, 255, 127) note over Client(Java),MonadoService: ipc Client(Java) ->>+ MonadoService: bindService MonadoService ->>+ IMonado.Stub: new MonadoImpl IMonado.Stub -->>- MonadoService: binder MonadoService -->>- Client(Java): binder end # end rect rgb(127, 255, 127) rect rgb(127, 255, 127) note over Client(Java),MonadoService: ipc Client(Java) ->>+ IMonado.Stub:createSurface IMonado.Stub -->>- Client(Java) : True end # end rect rgb(127, 255, 127) rect rgb(127, 255, 127) note over Client(Java),MonadoService: ipc Client(Java) ->>+ IMonado.Stub:connect IMonado.Stub -->>- Client(Java) : return 0 end # end rect rgb(127, 255, 127) Client(Java) -->>- ipc_client_android:return oursFd ipc_client_android -->>- ipc_client_instance: return ipc_client_android_blocking_connect note left of ipc_client_android: ipc_connect() return True note right of ipc_client_instance: some import steps : note right of ipc_client_instance: ipc_call_instance_get_shm_fd note right of ipc_client_instance: ipc_call_system_set_client_info ipc_client_instance -->>- target: return 0 as OK target -->>- oxr_instance: return 0 as OK oxr_instance ->>- oxr_api_instance: return XR_SUCCESS oxr_api_instance -->>- Loader: return XR_SUCCESS end # rect rgb(200, 150, 255) Loader -->>-Applicaiton: *out_instance end # rect rgb(191, 223, 255)
IMonado.createSurface
在建立IPC通讯的初期,Client会调用IMonado.createSurface创建Surface,由于我们是打开了canDrawOverOtherApps的选项,因此最终的window是由Server端,也就是MonadoService进程所持有的。
- 在MonadoService端有一个比较有意思的点是,当srufaceCreated回调触发后,会通过jni去创建一个Server,这个Server主要是做epoll轮询
调用流程图如下:
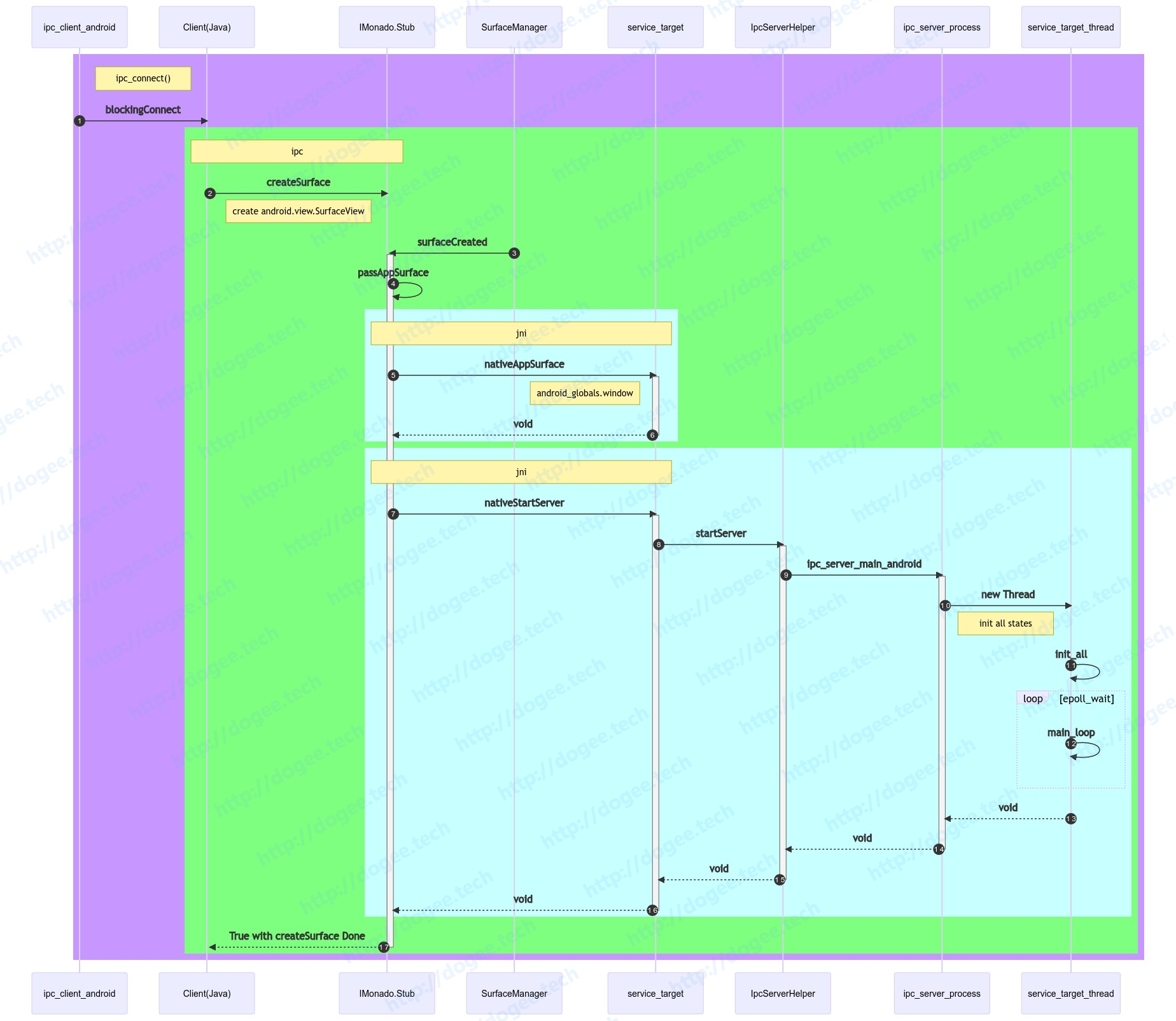
sequenceDiagram
autonumber
rect rgb(200, 150, 255)
note right of ipc_client_android: ipc_connect()
ipc_client_android ->>+ Client(Java):blockingConnect
rect rgb(127, 255, 127)
note over Client(Java),IMonado.Stub: ipc
Client(Java) ->>+ IMonado.Stub:createSurface
note left of IMonado.Stub: create android.view.SurfaceView
SurfaceManager ->>+ IMonado.Stub:surfaceCreated
IMonado.Stub ->> IMonado.Stub:passAppSurface
rect rgb(200, 255, 255)
note over IMonado.Stub,service_target: jni
IMonado.Stub ->>+ service_target:nativeAppSurface
note left of service_target: android_globals.window
service_target -->>- IMonado.Stub:void
end #rect rgb(200, 255, 255)
rect rgb(200, 255, 255)
note over IMonado.Stub,service_target: jni
IMonado.Stub ->>+ service_target:nativeStartServer
service_target ->>+ IpcServerHelper:startServer
IpcServerHelper ->>+ ipc_server_process:ipc_server_main_android
ipc_server_process ->> service_target_thread: new Thread
note right of ipc_server_process: init all states
service_target_thread ->> service_target_thread:init_all
loop epoll_wait
service_target_thread->>service_target_thread: main_loop
end
service_target_thread -->> ipc_server_process: void
ipc_server_process -->>- IpcServerHelper: void
IpcServerHelper -->>- service_target : void
service_target -->>- IMonado.Stub: void
end # rect rgb(200, 255, 255)
IMonado.Stub -->>- Client(Java): True with createSurface Done
end # end ipc rect rgb(127, 255, 127)
end
IMonado.connect
connect的部分比较简单,主要是把Client端创建的socket fd给到Server端,调用流程图仅展示到ipc_server_mainloop_add_fd。
后续的业务流程可以参考后面的章节:Client connected
调用流程图如下:
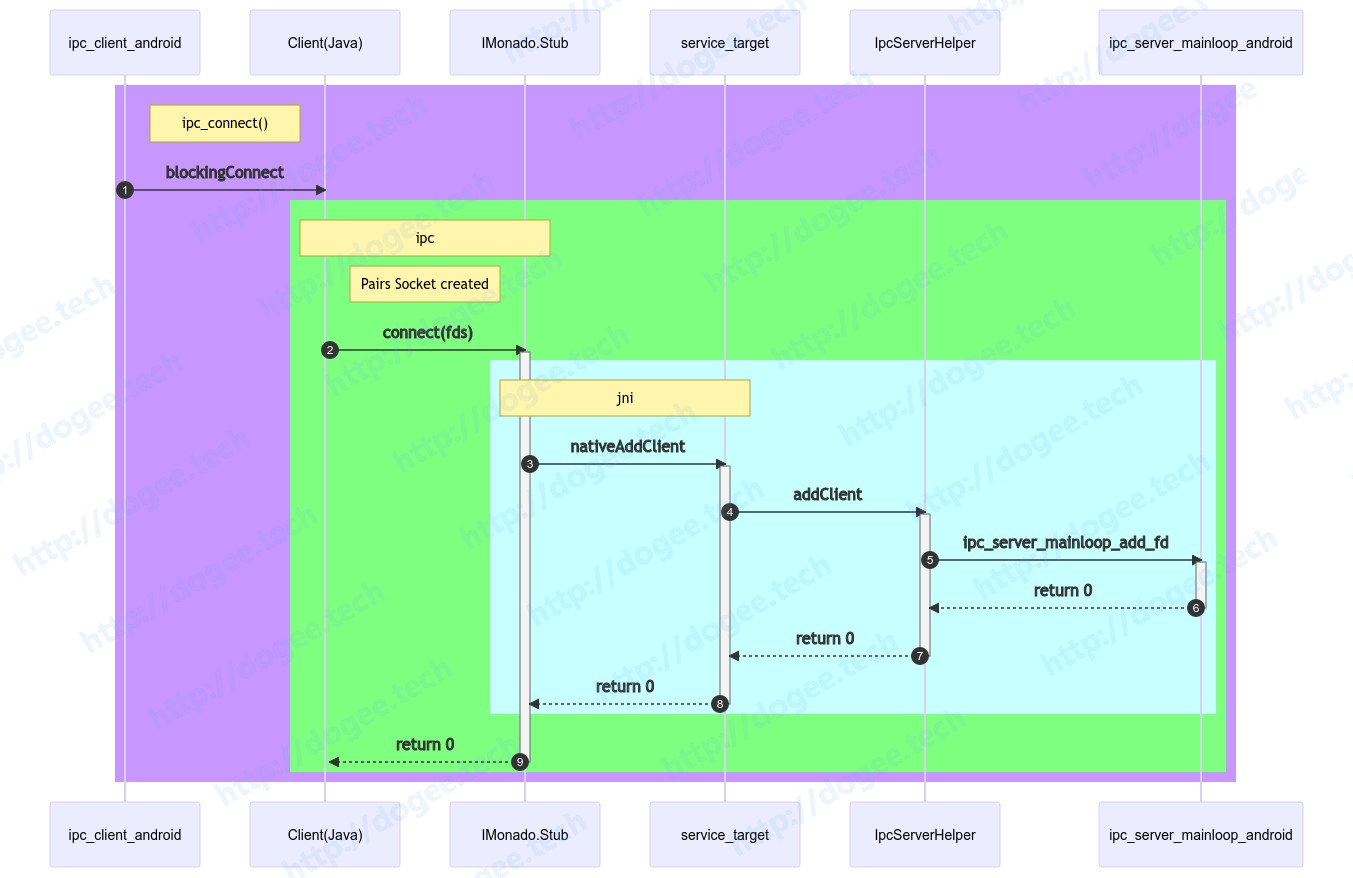
sequenceDiagram autonumber rect rgb(200, 150, 255) note right of ipc_client_android: ipc_connect() ipc_client_android ->>+ Client(Java):blockingConnect rect rgb(127, 255, 127) note over Client(Java),IMonado.Stub: ipc note right of Client(Java): Pairs Socket created Client(Java) ->>+ IMonado.Stub: connect(fds) rect rgb(200, 255, 255) note over IMonado.Stub,service_target: jni IMonado.Stub ->>+ service_target: nativeAddClient service_target ->>+ IpcServerHelper: addClient IpcServerHelper ->>+ ipc_server_mainloop_android:ipc_server_mainloop_add_fd ipc_server_mainloop_android -->>- IpcServerHelper:return 0 IpcServerHelper -->>- service_target:return 0 service_target -->>- IMonado.Stub:return 0 end # rect rgb(200, 255, 255) IMonado.Stub -->>- Client(Java):return 0 end #rect rgb(127, 255, 127) end
Server Thread
ipc_server_main_android在Out of process的流程中,这个部分有必要单独拿出来看一下,主要有两个初始化函数:
static int init_all(struct ipc_server *s)static void init_server_state(struct ipc_server *s)
调用的流程图如下: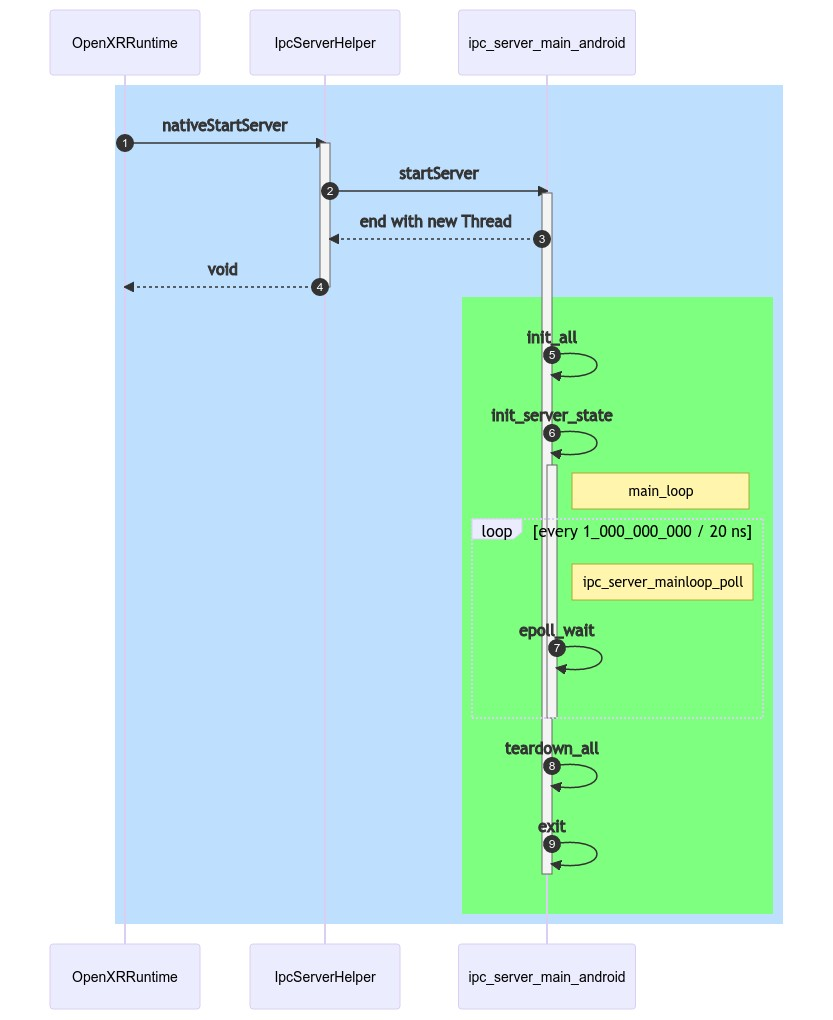
sequenceDiagram
autonumber
rect rgb(191, 223, 255)
# new thread with ipc_server_main_android
OpenXRRuntime ->>+ IpcServerHelper: nativeStartServer
IpcServerHelper ->> ipc_server_main_android:startServer
activate ipc_server_main_android
ipc_server_main_android -->> IpcServerHelper: end with new Thread
IpcServerHelper -->>- OpenXRRuntime: void
rect rgb(127, 255, 127)
ipc_server_main_android ->> ipc_server_main_android: init_all
ipc_server_main_android ->> ipc_server_main_android: init_server_state
activate ipc_server_main_android
note right of ipc_server_main_android:main_loop
loop every 1_000_000_000 / 20 ns
note right of ipc_server_main_android:ipc_server_mainloop_poll
ipc_server_main_android ->> ipc_server_main_android: epoll_wait
end #loop
deactivate ipc_server_main_android
ipc_server_main_android ->> ipc_server_main_android: teardown_all
ipc_server_main_android ->> ipc_server_main_android: exit
deactivate ipc_server_main_android
end #rect rgb(127, 255, 127)
end #rect rgb(191, 223, 255)
另外在代码中还有一个比较有意思的地方是,在最早进行oxr_instance_create的时候:
|
|
这里调用
xrt_instance_create时,我们实际跑的是target.c中的:xrt_instance_create。- 因为是在Application进程,调用的是libopenxr_runtime.so,所以Client端,xrt_instance实际是:
struct ipc_client_instance中的base成员变量:struct xrt_instance base - 但是由于base是
struct ipc_client_instance中的第一个成员,实际指针地址就是struct ipc_client_instance
在C语言中这样的
struct定义其实有点类似于C++中的类,也即xrt_instance是t_instance和ipc_client_instance的父类,使用者可以通过强制类型转换,灵活的在不同的代码上下文视该地址为不同对象。这部分技巧在远古feature phone时代经常使用,现在已经渐渐失传了,too old too useless。123456789101112131415161718192021xrt/targets/openxr/target.c......// Insert the on load constructor to setup trace marker.U_TRACE_TARGET_SETUP(U_TRACE_WHICH_OPENXR)// Forward declarationintipc_instance_create(struct xrt_instance_info *i_info, struct xrt_instance **out_xinst);intxrt_instance_create(struct xrt_instance_info *i_info, struct xrt_instance **out_xinst){u_trace_marker_init();XRT_TRACE_MARKER();return ipc_instance_create(i_info, out_xinst);}......- 因为是在Application进程,调用的是libopenxr_runtime.so,所以Client端,xrt_instance实际是:
但是在
ipc_server_main_android中,当我们init_all的时候调用的xrt_instance_create,这个时候调用的是target_instance.c中的实现,这个是属于libmonado_service.so,因此在server端,xrt_instance实际是:struct t_instance12345678910111213141516171819202122232425xrt/targets/common/target_instance.cintxrt_instance_create(struct xrt_instance_info *i_info, struct xrt_instance **out_xinst){struct xrt_prober *xp = NULL;u_trace_marker_init();int ret = xrt_prober_create_with_lists(&xp, &target_lists);if (ret < 0) {return ret;}struct t_instance *tinst = U_TYPED_CALLOC(struct t_instance);tinst->base.select = t_instance_select;tinst->base.create_system_compositor = t_instance_create_system_compositor;tinst->base.get_prober = t_instance_get_prober;tinst->base.destroy = t_instance_destroy;tinst->xp = xp;*out_xinst = &tinst->base;return 0;}
这个部分需要结合CMakeLists.txt来重新看一下。
init_all
在server thread初始化的地方,有一个比较重要的函数是init_all,其中有几个比较重要的点:
xrt_instance_createxrt_instance_selectinit_idevinit_tracking_originsxrt_instance_create_system_compositorinit_shmipc_server_mainloop_init
|
|
main_loop
Runtime端Server thread的主要作用:
在
init_all中初始化的三个fd:ml->pipe_read,ml->pipe_write,ml->epoll_fdml->pipe_read,ml->pipe_write是通过int pipe(int[2] pfd);创建的ml->epoll_fd是通过int epoll_create1(int flags);创建的,对应的是ml->pipe_read,监听ml->pipe_write的写入操作- 12345678910111213141516171819202122232425262728293031323334353637383940xrt/ipc/server/ipc_server_mainloop_android.cintipc_server_mainloop_init(struct ipc_server_mainloop *ml){int ret = init_pipe(ml);......ret = init_epoll(ml);......return 0;}static intinit_pipe(struct ipc_server_mainloop *ml){int pipefd[2];int ret = pipe(pipefd);......ml->pipe_read = pipefd[0];ml->pipe_write = pipefd[1];return 0;}static intinit_epoll(struct ipc_server_mainloop *ml){int ret = epoll_create1(EPOLL_CLOEXEC);......pthread_mutex_init(&ml->client_push_mutex, NULL);pthread_cond_init(&ml->accept_cond, NULL);pthread_mutex_init(&ml->accept_mutex, NULL);ml->epoll_fd = ret;struct epoll_event ev = {0};ev.events = EPOLLIN;ev.data.fd = ml->pipe_read;ret = epoll_ctl(ml->epoll_fd, EPOLL_CTL_ADD, ml->pipe_read, &ev);......return 0;}
main loop中的业务逻辑相对来说就简单很多了,主要就是在等待
ml->pipe_write的写入操作。当有写入操作过来的时候,会调用到
static void handle_listen(struct ipc_server *vs, struct ipc_server_mainloop *ml)
|
|
static void handle_listen(struct ipc_server *vs, struct ipc_server_mainloop *ml)的部分在后面的章节分析。
Client connected
在IMonado.connect的章节,我们分析到了函数:ipc_server_mainloop_add_fd,这里展开看一下。
抛开一些条件锁的逻辑,整个代码还是比较简单的,主要就是使用
ssize_t write(int fd, const void *buf, size_t count);写入fd这里传入的
newfd对应的是:ParcelFileDescriptor.createSocketPair();的fds[1],不同于pipe的实现,这里是SocketPair,即可读可写- 12345678910public int blockingConnect(Context context_, String packageName) {......try {ParcelFileDescriptor[] fds = ParcelFileDescriptor.createSocketPair();ours = fds[0];theirs = fds[1];monado.connect(theirs);}......}
Thread1:RPC Binder
ipc_server_mainloop_add_fd整体代码如下:
- 往
ml->pipe_write写入了newfd的值 - 等待条件变量
ml->accept_cond
|
|
Thread2:Server Thread
由于ml->pipe_write写入了newfd的值,因此在ml->epoll_fd上就会有事件过来,Server Thread端:
epoll_wait的return值就会是非0,进而会进运行到handle_listen12345678910111213141516xrt/ipc/server/ipc_server_process.cvoidipc_server_mainloop_poll(struct ipc_server *vs, struct ipc_server_mainloop *ml){int epoll_fd = ml->epoll_fd;......int ret = epoll_wait(epoll_fd, events, NUM_POLL_EVENTS, NO_SLEEP);......for (int i = 0; i < ret; i++) {// Somebody new at the door.if (events[i].data.fd == ml->pipe_read) {handle_listen(vs, ml);}}}在
handle_listen中会:- 读取到newfd的值,并赋予
ml->last_accepted_fd - 调用:
ipc_server_start_client_listener_thread(vs, newfd); - 激活条件变量
ml->accept_cond,从而ipc_server_mainloop_add_fd可以继续往下走
1234567891011121314151617181920xrt/ipc/server/ipc_server_process.cstatic voidhandle_listen(struct ipc_server *vs, struct ipc_server_mainloop *ml){int newfd = 0;pthread_mutex_lock(&ml->accept_mutex);// 1.读取到newfd的值,并赋予`ml->last_accepted_fd`if (read(ml->pipe_read, &newfd, sizeof(newfd)) == sizeof(newfd)) {......ml->last_accepted_fd = newfd;// 2.调用:`ipc_server_start_client_listener_thread(vs, newfd);`ipc_server_start_client_listener_thread(vs, newfd);// 3.激活条件变量`ml->accept_cond`,从而`ipc_server_mainloop_add_fd`可以继续往下走pthread_cond_broadcast(&ml->accept_cond);} else {......}pthread_mutex_unlock(&ml->accept_mutex);}- 读取到newfd的值,并赋予
Thread3:new Client Thread
以上是完成了一个IMonado.connect的RPC调用,但是有一个函数:ipc_server_start_client_listener_thread需要做进一步拆解。
#define IPC_MAX_CLIENTS 8,通过该值我们可以确定在monado方案下,最多可以同时存在8个client- 把对应的
fd信息给到ics->imc.socket_fd,这里的ics为client thread独有的
|
|
Thread对应的enter point:ipc_server_client_thread,简单梳理一下:
- 通过传入的fd,创建epoll fd,带入的参数为
EPOLLIN,因此是监听作用 - 读取的数据中
ipc_command_t *ipc_command = (uint32_t *)buf;,前四个字节视为ipc_command - 通过
ipc_dispatch(ics, ipc_command);处理对应的业务。
|
|
Command list如下
- 生成的部分参考:
xrt/ipc/CMakeLists.txt - 简单认知:带有IPC COMMOND的都是在Runtime进程完成的RPC调用
12345678910111213141516171819202122232425262728293031323334353637xrt/targets/openxr_android/.cxx/cmake/outOfProcessDebug/arm64-v8a/src/xrt/ipc/ipc_protocol_generated.htypedef enum ipc_command{IPC_ERR = 0,IPC_INSTANCE_GET_SHM_FD,IPC_SYSTEM_GET_CLIENT_INFO,IPC_SYSTEM_SET_CLIENT_INFO,IPC_SYSTEM_GET_CLIENTS,IPC_SYSTEM_SET_PRIMARY_CLIENT,IPC_SYSTEM_SET_FOCUSED_CLIENT,IPC_SYSTEM_TOGGLE_IO_CLIENT,IPC_SYSTEM_TOGGLE_IO_DEVICE,IPC_SYSTEM_COMPOSITOR_GET_INFO,IPC_SESSION_CREATE,IPC_SESSION_BEGIN,IPC_SESSION_END,IPC_SESSION_DESTROY,IPC_COMPOSITOR_GET_INFO,IPC_COMPOSITOR_PREDICT_FRAME,IPC_COMPOSITOR_WAIT_WOKE,IPC_COMPOSITOR_BEGIN_FRAME,IPC_COMPOSITOR_DISCARD_FRAME,IPC_COMPOSITOR_LAYER_SYNC,IPC_COMPOSITOR_POLL_EVENTS,IPC_SWAPCHAIN_CREATE,IPC_SWAPCHAIN_IMPORT,IPC_SWAPCHAIN_WAIT_IMAGE,IPC_SWAPCHAIN_ACQUIRE_IMAGE,IPC_SWAPCHAIN_RELEASE_IMAGE,IPC_SWAPCHAIN_DESTROY,IPC_DEVICE_UPDATE_INPUT,IPC_DEVICE_GET_TRACKED_POSE,IPC_DEVICE_GET_HAND_TRACKING,IPC_DEVICE_GET_VIEW_POSE,IPC_DEVICE_SET_OUTPUT,} ipc_command_t;- 生成的部分参考:
Server & Client Flow
BinderThread,ServerThread,ClientThread的调用关系如下:
- BinderThread在Android中有16条,每次是随机分配的,因此命名为BinderThread#X
- ServerThread只要一条,主要是监听
ml->pipe_write的写入动作,读出client端传入的theres newfd - ClientThread最多可以有8条,因此命名为ClientThread#X,每次Client的
connect都会重新新建thread(总数小于8的情况下)
调用流程图如下: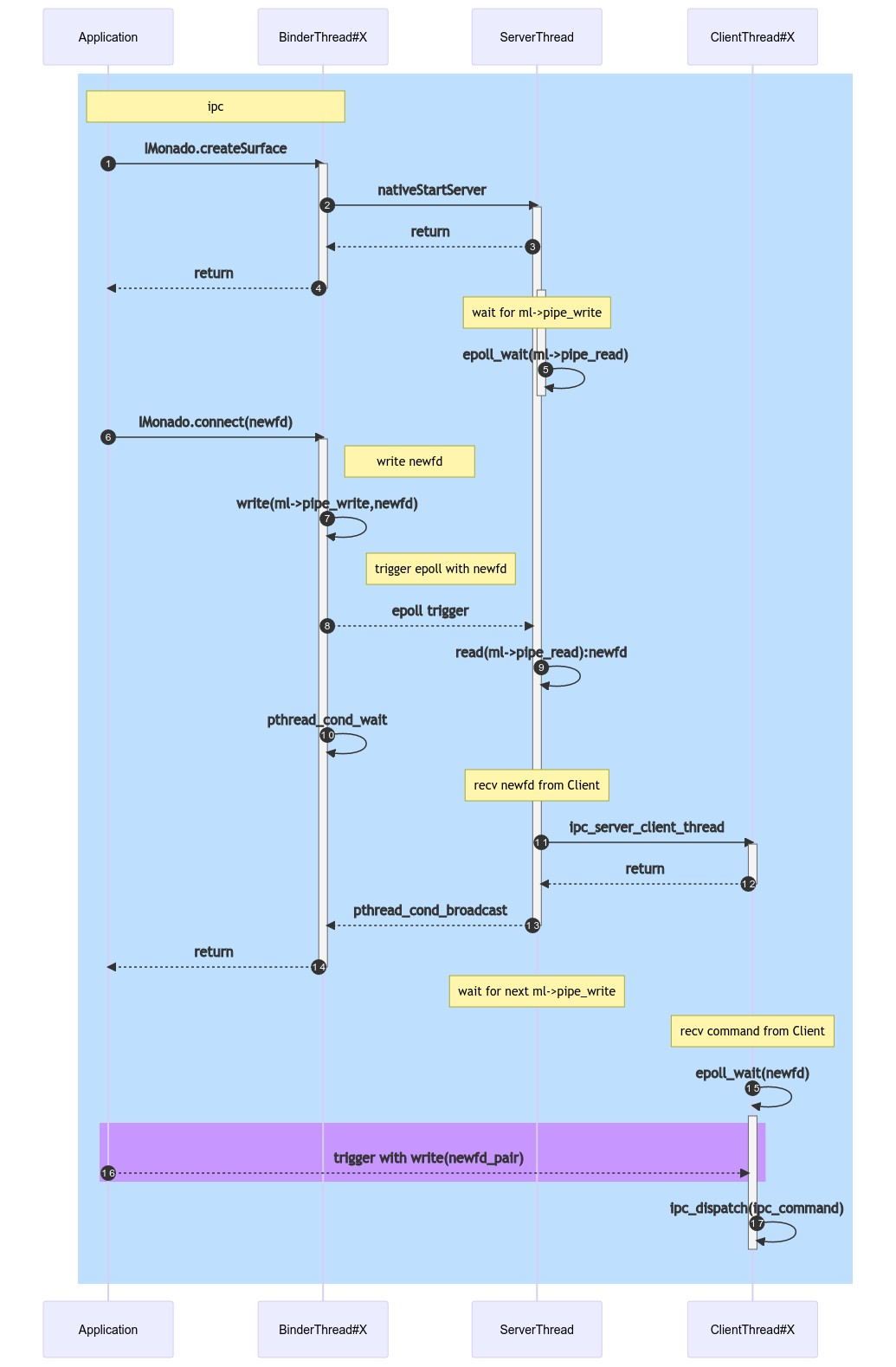
sequenceDiagram autonumber rect rgb(191, 223, 255) note over Application,BinderThread#X: ipc Application ->>+ BinderThread#X: IMonado.createSurface BinderThread#X ->>+ ServerThread: nativeStartServer ServerThread -->> BinderThread#X: return BinderThread#X -->>- Application: return activate ServerThread note over ServerThread: wait for ml->pipe_write ServerThread ->> ServerThread: epoll_wait(ml->pipe_read) deactivate ServerThread Application ->>+ BinderThread#X: IMonado.connect(newfd) note right of BinderThread#X: write newfd BinderThread#X ->> BinderThread#X: write(ml->pipe_write,newfd) note left of ServerThread: trigger epoll with newfd BinderThread#X -->> ServerThread: epoll trigger ServerThread ->> ServerThread: read(ml->pipe_read):newfd BinderThread#X ->> BinderThread#X : pthread_cond_wait note over ServerThread: recv newfd from Client ServerThread ->>+ ClientThread#X: ipc_server_client_thread ClientThread#X -->>- ServerThread: return ServerThread -->> BinderThread#X:pthread_cond_broadcast deactivate ServerThread BinderThread#X -->>- Application: return note over ServerThread: wait for next ml->pipe_write note over ClientThread#X: recv command from Client ClientThread#X ->>+ ClientThread#X: epoll_wait(newfd) rect rgb(200, 150, 255) Application -->> ClientThread#X: trigger with write(newfd_pair) end #rect rgb(200, 150, 255) ClientThread#X ->>- ClientThread#X: ipc_dispatch(ipc_command) end #rect rgb(191, 223, 255)
Session
xrCreateSession
RPC Call Flow
遵循之前的Server Thread以及Client Thread架构,这边需要区分两个instance
- 在Application进程端的XrInstance是
struct oxr_instance的指针其中的struct xrt_instance *xinst成员变量- 实际是
struct ipc_client_instance
- 实际是
- 在Runtime进程端的Instance实际是
struct t_instance
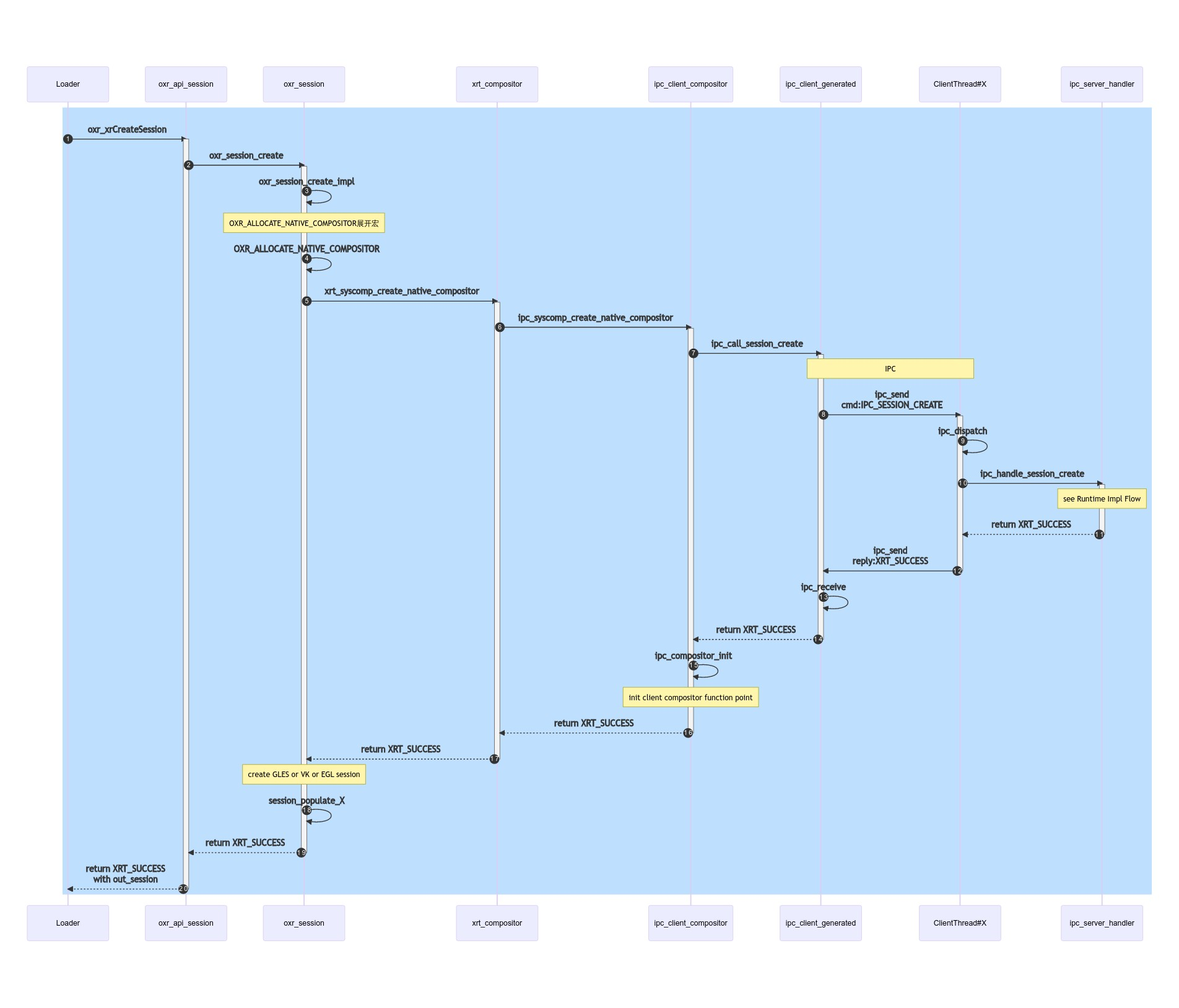
sequenceDiagram autonumber rect rgb(191, 223, 255) # call for RPC Loader ->>+ oxr_api_session: oxr_xrCreateSession oxr_api_session ->>+ oxr_session: oxr_session_create oxr_session ->> oxr_session: oxr_session_create_impl note over oxr_session: OXR_ALLOCATE_NATIVE_COMPOSITOR展开宏 oxr_session ->> oxr_session: OXR_ALLOCATE_NATIVE_COMPOSITOR oxr_session ->>+ xrt_compositor:xrt_syscomp_create_native_compositor xrt_compositor ->>+ ipc_client_compositor: ipc_syscomp_create_native_compositor ipc_client_compositor ->>+ ipc_client_generated: ipc_call_session_create note over ipc_client_generated,ClientThread#X: IPC ipc_client_generated ->>+ ClientThread#X:ipc_send
cmd:IPC_SESSION_CREATE ClientThread#X ->> ClientThread#X: ipc_dispatch ClientThread#X ->>+ ipc_server_handler: ipc_handle_session_create note over ipc_server_handler: see Runtime Impl Flow ipc_server_handler -->>- ClientThread#X: return XRT_SUCCESS # call end RPC ClientThread#X ->>- ipc_client_generated:ipc_send
reply:XRT_SUCCESS ipc_client_generated ->> ipc_client_generated: ipc_receive ipc_client_generated -->>- ipc_client_compositor: return XRT_SUCCESS ipc_client_compositor ->> ipc_client_compositor: ipc_compositor_init note over ipc_client_compositor: init client compositor function point ipc_client_compositor -->>- xrt_compositor: return XRT_SUCCESS xrt_compositor -->>- oxr_session: return XRT_SUCCESS note over oxr_session: create GLES or VK or EGL session oxr_session ->> oxr_session : session_populate_X oxr_session -->>- oxr_api_session: return XRT_SUCCESS oxr_api_session -->>- Loader: return XRT_SUCCESS
with out_session end #rect rgb(191, 223, 255)
Runtime Impl Flow
Runtime端的业务实作比较简单明了,在Out of Process的模式下,通过IPC_COMMAND的形式发需求发送过来,如RPC Call Flow所述:
- 在Runtime进程端的Instance是通过
struct t_instance内的数据结构struct xrt_instance base- 对应初始化的部分函数指针:
tinst->base.create_system_compositor = t_instance_create_system_compositor;
- 对应初始化的部分函数指针:
因此整个Call Flow如下:
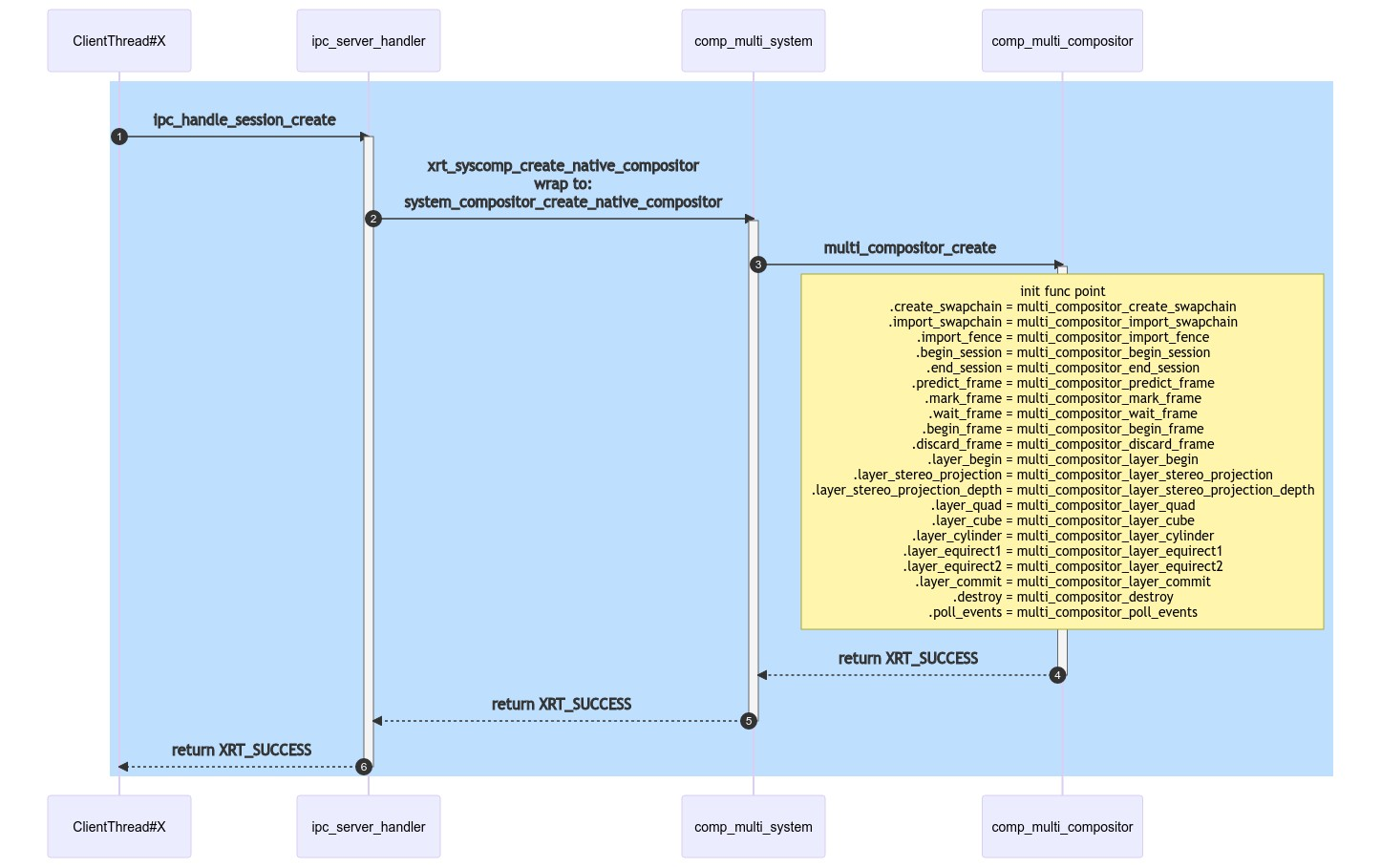
sequenceDiagram autonumber rect rgb(191, 223, 255) ClientThread#X ->>+ ipc_server_handler:ipc_handle_session_create ipc_server_handler ->>+ comp_multi_system: xrt_syscomp_create_native_compositor
wrap to:
system_compositor_create_native_compositor comp_multi_system ->>+ comp_multi_compositor:multi_compositor_create note over comp_multi_compositor: init func point
.create_swapchain = multi_compositor_create_swapchain
.import_swapchain = multi_compositor_import_swapchain
.import_fence = multi_compositor_import_fence
.begin_session = multi_compositor_begin_session
.end_session = multi_compositor_end_session
.predict_frame = multi_compositor_predict_frame
.mark_frame = multi_compositor_mark_frame
.wait_frame = multi_compositor_wait_frame
.begin_frame = multi_compositor_begin_frame
.discard_frame = multi_compositor_discard_frame
.layer_begin = multi_compositor_layer_begin
.layer_stereo_projection = multi_compositor_layer_stereo_projection
.layer_stereo_projection_depth = multi_compositor_layer_stereo_projection_depth
.layer_quad = multi_compositor_layer_quad
.layer_cube = multi_compositor_layer_cube
.layer_cylinder = multi_compositor_layer_cylinder
.layer_equirect1 = multi_compositor_layer_equirect1
.layer_equirect2 = multi_compositor_layer_equirect2
.layer_commit = multi_compositor_layer_commit
.destroy = multi_compositor_destroy
.poll_events = multi_compositor_poll_events; comp_multi_compositor -->>- comp_multi_system: return XRT_SUCCESS comp_multi_system -->>- ipc_server_handler: return XRT_SUCCESS ipc_server_handler -->>- ClientThread#X: return XRT_SUCCESS end # rect rgb(191, 223, 255)
Impl Code
其实在代码侧是分为两块的:
- 一个是运行在Application进程的,是通过broker以ContentProvider给出的so:libopenxr_monado.so
- 这个是通过dlopen加载的,所以直接吃在Application的进程内
- 另外一个是运行在RuntimeServer进程的libmonado-service.so
- 这个部分是以jni的方式load进去的
broker后load so的代码这边就不做展开了,后面重新写文档介绍整个openxr runtime load的时候再说了,一言以蔽之就是找到so,然后dlopen。
主要代码流程如下:
Loader-> Runtime
xrt/state_trackers/oxr/oxr_api_session.c,oxr_xrCreateSession初始化
struct oxr_instance *inst;,其实就是强制转化inst = (struct oxr_instance *)((uintptr_t)instance)- 12345678910111213省略无关参数后宏:#define OXR_VERIFY_INSTANCE_AND_INIT_LOG(_, thing, new_thing, _) \_OXR_VERIFY_AND_SET_AND_INIT(_, thing, new_thing, oxr_instance, _, _, _)#define _OXR_VERIFY_AND_SET_AND_INIT(_, thing, new_thing, oxr_thing, _, _, _) \do { ...... \new_thing = (struct oxr_thing *)((uintptr_t)thing); \...... \} while (0)OXR_VERIFY_INSTANCE_AND_INIT_LOG(&log, instance, inst, "xrCreateSession");<=>inst = (struct oxr_instance *)((uintptr_t)instance)
从api层调用到wrap层的函数:
oxr_session_create拿到
sess的实例后以out参数的形式返回保存到
inst的session队尾
12345678910111213141516171819202122232425262728xrt/state_trackers/oxr/oxr_api_session.cXrResultoxr_xrCreateSession(XrInstance instance, const XrSessionCreateInfo *createInfo, XrSession *out_session){......XrResult ret;struct oxr_instance *inst;struct oxr_session *sess, **link;......// 1.inst = (struct oxr_instance *)((uintptr_t)instance)OXR_VERIFY_INSTANCE_AND_INIT_LOG(&log, instance, inst, "xrCreateSession");......// 2.从api层调用到wrap层的函数:`oxr_session_create`ret = oxr_session_create(&log, &inst->system, createInfo, &sess);......// 3.拿到`sess`的实例后以out参数的形式返回*out_session = oxr_session_to_openxr(sess);/* Add to session list */// 4.保存到`inst`的`session`队尾link = &inst->sessions;while (*link) {link = &(*link)->next;}*link = sess;return XR_SUCCESS;}xrt/state_trackers/oxr/oxr_session.c,oxr_session_create- 需要注意的是overlay info,这里会带有z_order,所以session其实是有层级关系的(后续待确认)
- 调用实际的impl函数
- 完成semaphore的初始化
1234567891011121314151617181920212223242526272829xrt/state_trackers/oxr/oxr_session.cXrResultoxr_session_create(struct oxr_logger *log,struct oxr_system *sys,const XrSessionCreateInfo *createInfo,struct oxr_session **out_session){struct oxr_session *sess = NULL;......if (overlay_info) {xsi.is_overlay = true;xsi.flags = overlay_info->createFlags;xsi.z_order = overlay_info->sessionLayersPlacement;}......XrResult ret = oxr_session_create_impl(log, sys, createInfo, &xsi, &sess);......// Init the begin/wait frame semaphore.os_semaphore_init(&sess->sem, 1);sess->active_wait_frames = 0;os_mutex_init(&sess->active_wait_frames_lock);......*out_session = sess;return ret;}
Before RPC
xrt/state_trackers/oxr/oxr_session.c,oxr_session_create_impl123456789101112131415161718192021222324252627282930313233343536373839404142static XrResultoxr_session_create_impl(struct oxr_logger *log,struct oxr_system *sys,const XrSessionCreateInfo *createInfo,const struct xrt_session_info *xsi,struct oxr_session **out_session){......XrGraphicsBindingOpenGLESAndroidKHR const *opengles_android = OXR_GET_INPUT_FROM_CHAIN(createInfo, XR_TYPE_GRAPHICS_BINDING_OPENGL_ES_ANDROID_KHR, XrGraphicsBindingOpenGLESAndroidKHR);if (opengles_android != NULL) {......OXR_SESSION_ALLOCATE(log, sys, *out_session);OXR_ALLOCATE_NATIVE_COMPOSITOR(log, xsi, *out_session);return oxr_session_populate_gles_android(log, sys, opengles_android, *out_session);}XrGraphicsBindingVulkanKHR const *vulkan =OXR_GET_INPUT_FROM_CHAIN(createInfo, XR_TYPE_GRAPHICS_BINDING_VULKAN_KHR, XrGraphicsBindingVulkanKHR);if (vulkan != NULL) {......OXR_SESSION_ALLOCATE(log, sys, *out_session);OXR_ALLOCATE_NATIVE_COMPOSITOR(log, xsi, *out_session);return oxr_session_populate_vk(log, sys, vulkan, *out_session);}XrGraphicsBindingEGLMNDX const *egl =OXR_GET_INPUT_FROM_CHAIN(createInfo, XR_TYPE_GRAPHICS_BINDING_EGL_MNDX, XrGraphicsBindingEGLMNDX);if (egl != NULL) {......OXR_SESSION_ALLOCATE(log, sys, *out_session);OXR_ALLOCATE_NATIVE_COMPOSITOR(log, xsi, *out_session);return oxr_session_populate_egl(log, sys, egl, *out_session);}......}这段代码就比较trick了,属于远古C语言常用的各种技巧了
首先是通过宏来控制编译的内容,这个比较低级一些,这边有三种我们打开的macro:OPENGL_ES,VULKAN,EGL
其次是在初始化的过程中,使用宏来复写代码,这个就比较搞人了,因为Ctrl+F会搜不到:
1234567891011121314do { \xrt_result_t xret = xrt_syscomp_create_native_compositor((SESS)->sys->xsysc, (XSI), &(SESS)->xcn); \(xret == XRT_ERROR_MULTI_SESSION_NOT_IMPLEMENTED) { \return oxr_error((LOG), XR_ERROR_LIMIT_REACHED, ); \} (xret != XRT_SUCCESS) { \return oxr_error((LOG), XR_ERROR_RUNTIME_FAILURE, , \xret); \} \((SESS)->sys->xsysc->xmcc != NULL) { \xrt_syscomp_set_state((SESS)->sys->xsysc, &(SESS)->xcn->base, true, true); \xrt_syscomp_set_z_order((SESS)->sys->xsysc, &(SESS)->xcn->base, 0); \} \} while (false)
带着以上的认知和展开的宏,我们来看下面的代码:
根据Client传入的不同参数,我们可以选型的创建OPENGL_ES,VULKAN,EGL三种不同的session
xrt_compositor_native是通过宏OXR_ALLOCATE_NATIVE_COMPOSITOR来搞定的:xrt_syscomp_create_native_compositor1234567static inline xrt_result_txrt_syscomp_create_native_compositor(struct xrt_system_compositor *xsc,const struct xrt_session_info *xsi,struct xrt_compositor_native **out_xcn){return xsc->create_native_compositor(xsc, xsi, out_xcn);}这里我们带出来一个问题,
xsc是从哪里来的,溯源一下其实xsc是inst->sys->xsyscinst->sys->xsc实际初始化是在oxr_instance_create的时候搞定的:&sys->xsysc1234567891011121314151617181920212223XrResultoxr_instance_create(struct oxr_logger *log,const XrInstanceCreateInfo *createInfo,const struct oxr_extension_status *extensions,struct oxr_instance **out_instance){......// Create the compositor, if we are not headless.if (!inst->extensions.MND_headless) {xret = xrt_instance_create_system_compositor(inst->xinst, dev, &sys->xsysc);......}......}static inline intxrt_instance_create_system_compositor(struct xrt_instance *xinst,struct xrt_device *xdev,struct xrt_system_compositor **out_xsc){return xinst->create_system_compositor(xinst, xdev, out_xsc);}xinst->create_system_compositor的函数指针实际:ipc_client_instance_create_system_compositor1234567intipc_instance_create(struct xrt_instance_info *i_info, struct xrt_instance **out_xinst){......ii->base.create_system_compositor = ipc_client_instance_create_system_compositor;......}
因此我们直接看
ipc_client_create_system_compositor的实现,发现实际xsc->create_native_compositor的函数指针为:ipc_syscomp_create_native_compositor1234567891011121314intipc_client_create_system_compositor(struct ipc_connection *ipc_c,struct xrt_image_native_allocator *xina,struct xrt_device *xdev,struct xrt_system_compositor **out_xcs){struct ipc_client_compositor *c = U_TYPED_CALLOC(struct ipc_client_compositor);......c->system.create_native_compositor = ipc_syscomp_create_native_compositor;......*out_xcs = &c->system;......}
回到之前的代码,
xrt_syscomp_create_native_compositor实际就是调用ipc_syscomp_create_native_compositor- 这里就存在一次IPC通讯,隐藏在create_native_compositor中的ipc_call_session_create
12345678910111213141516xrt_result_tipc_syscomp_create_native_compositor(struct xrt_system_compositor *xsc,const struct xrt_session_info *xsi,struct xrt_compositor_native **out_xcn){......// IPC调用IPC_CALL_CHK(ipc_call_session_create(icc->ipc_c, xsi));if (res != XRT_SUCCESS) {return res;}// Needs to be done after session create call.ipc_compositor_init(icc, out_xcn);.......return XRT_SUCCESS;}
After RPC
刚才所有的故事都是因为一个宏:OXR_ALLOCATE_NATIVE_COMPOSITOR,这个宏回来之后就是创建具体的session了。
|
|
仅以OpenGL ES为例:
完成了egl so库的加载
做了一些gl/egl的初始化
完成了create_swapchain的函数指针赋值
12345678910111213141516171819202122232425XrResultoxr_session_populate_gles_android(struct oxr_logger *log,struct oxr_system *sys,XrGraphicsBindingOpenGLESAndroidKHR const *next,struct oxr_session *sess){void *so = dlopen("libEGL.so", RTLD_NOW | RTLD_LOCAL);......struct xrt_compositor_native *xcn = sess->xcn;struct xrt_compositor_gl *xcgl = NULL;xrt_result_t xret = xrt_gfx_provider_create_gl_egl( //xcn, //next->display, //next->config, //next->context, //get_proc_addr, //&xcgl); //......sess->compositor = &xcgl->base;sess->create_swapchain = oxr_swapchain_gl_create;return XR_SUCCESS;}
In RPC
这部分主要是在RuntimeServer进程中的,我们直接从收到IPC COMMAND:IPC_SESSION_CREATE开始
其实还是绕一圈去:
xrt_syscomp_create_native_compositor12345678910xrt_result_tipc_handle_session_create(volatile struct ipc_client_state *ics, const struct xrt_session_info *xsi){......struct xrt_compositor_native *xcn = NULL;......xrt_result_t xret = xrt_syscomp_create_native_compositor(ics->server->xsysc, xsi, &xcn);......return XRT_SUCCESS;}这部分的逻辑跟上面的Before RPC是一样的,就是在找:
ics->server->xsysc,这个对应的函数指针是谁。根据之前的认知,我们知道
ics,这个变量是在new Client Thread中设置的,顺便的我们看到ics->server实际是struct ipc_server123456789voidipc_server_start_client_listener_thread(struct ipc_server *vs, int fd){......ics->server = vs;......os_thread_start(&it->thread, ipc_server_client_thread, (void *)ics);......}struct ipc_server的部分是在init_all中初始化的,因此一并看下来的话会发现s->xsysc也是有初始化的:123456789static intinit_all(struct ipc_server *s){......int ret = xrt_instance_create(NULL, &s->xinst);......ret = xrt_instance_create_system_compositor(s->xinst, s->idevs[0].xdev, &s->xsysc);......}所以整个推导过程是:
xinst->create_system_compositor = t_instance_create_system_compositors->xsysc作为t_instance_create_system_compositor的out返回参数,对应的赋值:1234567891011static intt_instance_create_system_compositor(struct xrt_instance *xinst,struct xrt_device *xdev,struct xrt_system_compositor **out_xsysc){.......xrt_result_t ret = xrt_gfx_provider_create_system(xdev, &xsysc);......*out_xsysc = xsysc;......}12345678xrt_result_txrt_gfx_provider_create_system(struct xrt_device *xdev, struct xrt_system_compositor **out_xsysc){struct comp_compositor *c = U_TYPED_CALLOC(struct comp_compositor);c->base.base.base.begin_session = compositor_begin_session;......return comp_multi_create_system_compositor(&c->base.base, sys_info, out_xsysc);}1234567891011121314151617xrt_result_tcomp_multi_create_system_compositor(struct xrt_compositor_native *xcn,const struct xrt_system_compositor_info *xsci,struct xrt_system_compositor **out_xsysc){// msc is multi_system_compositor// msc->base is xrt_system_compositor// msc->xcn is xrt_compositor_nativestruct multi_system_compositor *msc = U_TYPED_CALLOC(struct multi_system_compositor);msc->base.create_native_compositor = system_compositor_create_native_compositor;......msc->xcn = xcn;......os_thread_helper_start(&msc->oth, thread_func, msc);*out_xsysc = &msc->base;......}最后这边是:
创建了一条thread,这个后续要到Multi-Compositor-Main的章节来说了,这条thread是伴随RuntimeServer初始化的时候创建。
123456static intinit_all(struct ipc_server *s) {......ret = xrt_instance_create_system_compositor(s->xinst, s->idevs[0].xdev, &s->xsysc);......}msc->base.create_native_compositor = system_compositor_create_native_compositor;
因此,整个调用:
123456789101112xrt_result_tipc_handle_session_create(volatile struct ipc_client_state *ics, const struct xrt_session_info *xsi){......struct xrt_compositor_native *xcn = NULL;......xrt_result_t xret = xrt_syscomp_create_native_compositor(ics->server->xsysc, xsi, &xcn);......ics->xc = &xcn->base;......return XRT_SUCCESS;}其实就是:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748static xrt_result_tsystem_compositor_create_native_compositor(struct xrt_system_compositor *xsc,const struct xrt_session_info *xsi,struct xrt_compositor_native **out_xcn){struct multi_system_compositor *msc = multi_system_compositor(xsc);return multi_compositor_create(msc, xsi, out_xcn);}xrt_result_tmulti_compositor_create(struct multi_system_compositor *msc,const struct xrt_session_info *xsi,struct xrt_compositor_native **out_xcn){......struct multi_compositor *mc = U_TYPED_CALLOC(struct multi_compositor);// msc is multi_system_compositor// mc is multi_compositor// mc->base is xrt_compositor_native// mc->base.base is xrt_compositormc->base.base.create_swapchain = multi_compositor_create_swapchain;mc->base.base.import_swapchain = multi_compositor_import_swapchain;mc->base.base.import_fence = multi_compositor_import_fence;mc->base.base.begin_session = multi_compositor_begin_session;mc->base.base.end_session = multi_compositor_end_session;mc->base.base.predict_frame = multi_compositor_predict_frame;mc->base.base.mark_frame = multi_compositor_mark_frame;mc->base.base.wait_frame = multi_compositor_wait_frame;mc->base.base.begin_frame = multi_compositor_begin_frame;mc->base.base.discard_frame = multi_compositor_discard_frame;mc->base.base.layer_begin = multi_compositor_layer_begin;mc->base.base.layer_stereo_projection = multi_compositor_layer_stereo_projection;mc->base.base.layer_stereo_projection_depth = multi_compositor_layer_stereo_projection_depth;mc->base.base.layer_quad = multi_compositor_layer_quad;mc->base.base.layer_cube = multi_compositor_layer_cube;mc->base.base.layer_cylinder = multi_compositor_layer_cylinder;mc->base.base.layer_equirect1 = multi_compositor_layer_equirect1;mc->base.base.layer_equirect2 = multi_compositor_layer_equirect2;mc->base.base.layer_commit = multi_compositor_layer_commit;mc->base.base.destroy = multi_compositor_destroy;mc->base.base.poll_events = multi_compositor_poll_events;mc->msc = msc;......*out_xcn = &mc->base;return XRT_SUCCESS;}
结论
ok,整个xrCreateSession,其实是:
- 在Server端对
multi_compositor的结构体做赋值。 - 这里出现了好几个compositor,他们之间是什么关系,具体是什么作用。(TODO uml)
- comp_compositor
- comp_base
- xrt_compositor_native
- xrt_compositor
- multi_system_compositor
- xrt_system_compositor
- multi_compositor
xrBeginSession
在monado的代码中begin sessin的部分主要有3处:
- Application进程的Begion Session
- RuntimeServer进程响应到的Begin Session
- Multi-Compositor Thread中的Begin Session,这个会在Multi-Compositor-Thread这一章来讲
Application
主要是根据不同的Application进程选择Type,决定了初始化时候的xrt_compositor类型和begin_session的函数指针
oxr_session_populate_gles_androidoxr_session_populate_egl- client_gl_compositor,client_gl_compositor_begin_session
oxr_session_populate_vk- client_vk_compositor,client_vk_compositor_begin_session
最终的调用flow都会汇聚到:ipc_compositor_begin_session,这个跟xrCreateSession是一样的,Application进程端的任务就结束了。
RuntimeServer
当收到来自Application进程的COMMAND:IPC_SESSION_BEGIN后
从ServerThread上带入的参数为
struct ipc_client_state *ics123456789101112xrt_result_tipc_handle_session_begin(volatile struct ipc_client_state *ics){......return xrt_comp_begin_session(ics->xc, 0);}static inline xrt_result_txrt_comp_begin_session(struct xrt_compositor *xc, enum xrt_view_type view_type){return xc->begin_session(xc, view_type);}这里的
ics->xc,根据之前在xrCreateSession中的流程,我们可以知道ics->xc = &xcn->base,而xcn = out_xcn, 又out_xcn= mc->base,因此ics->xc=&mc->base->base- 因此在
xc->begin_session=mc->base->base->begin_session= multi_compositor_begin_session
最终会调用到:
multi_compositor_begin_session12345678910static xrt_result_tmulti_compositor_begin_session(struct xrt_compositor *xc, enum xrt_view_type type){COMP_TRACE_MARKER();struct multi_compositor *mc = multi_compositor(xc);(void)mc;return XRT_SUCCESS;}- 其实什么也没有做!
xrEndSession
End的部分跟Begin比较类似,不再赘述了。后续以流程图的形式来呈现Session一个生命周期。
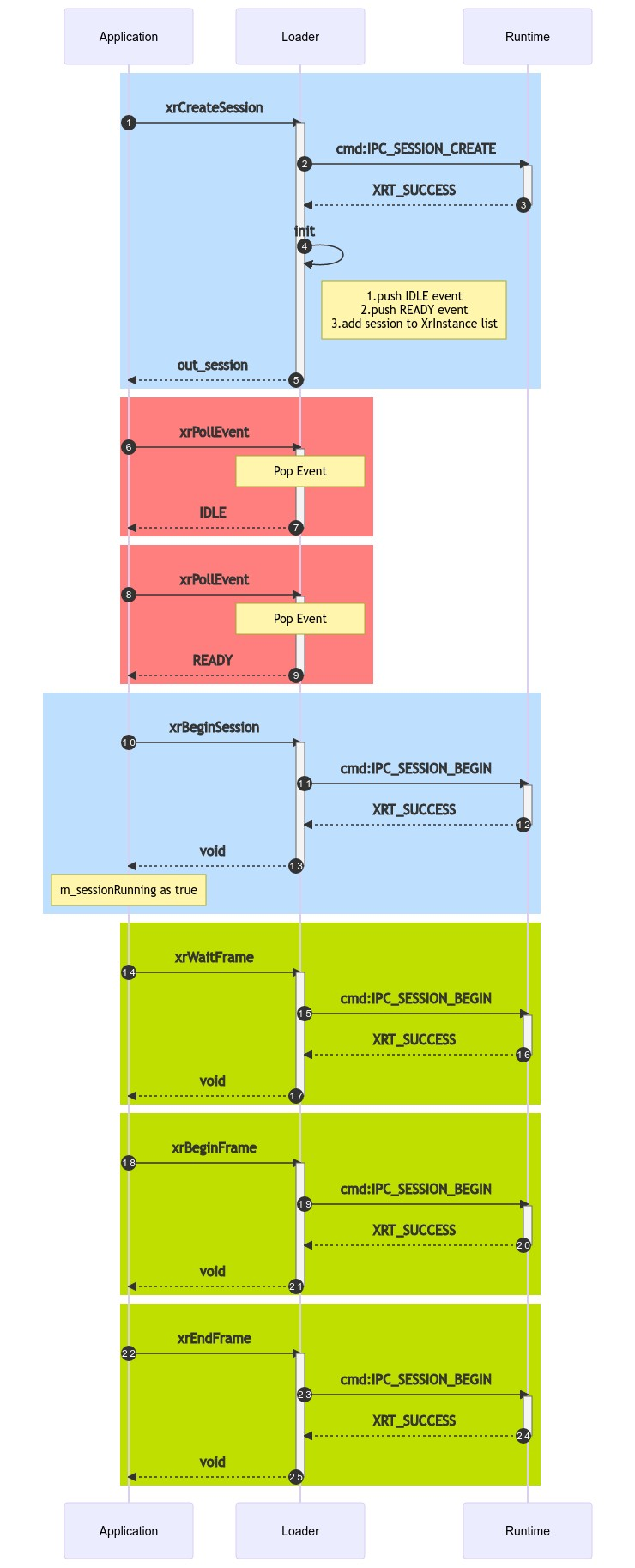
sequenceDiagram autonumber rect rgb(191, 223, 255) Application ->>+ Loader:xrCreateSession Loader ->>+ Runtime: cmd:IPC_SESSION_CREATE Runtime -->>- Loader: XRT_SUCCESS Loader ->> Loader: init note right of Loader: 1.push IDLE event
2.push READY event
3.add session to XrInstance list Loader -->>- Application: out_session end # rect rgb(191, 223, 255) rect rgb(255, 127, 127) Application ->>+ Loader:xrPollEvent note over Loader: Pop Event Loader -->>- Application: IDLE end #rect rgb(255, 127, 127) rect rgb(255, 127, 127) Application ->>+ Loader:xrPollEvent note over Loader: Pop Event Loader -->>- Application: READY end #rect rgb(255, 127, 127) rect rgb(191, 223, 255) Application ->>+ Loader:xrBeginSession Loader ->>+ Runtime: cmd:IPC_SESSION_BEGIN Runtime -->>- Loader: XRT_SUCCESS Loader -->>- Application: void note over Application: m_sessionRunning as true end #rect rgb(255, 127, 127) rect rgb(191, 223, 0) Application ->>+ Loader:xrWaitFrame Loader ->>+ Runtime: cmd:IPC_SESSION_BEGIN Runtime -->>- Loader: XRT_SUCCESS Loader -->>- Application: void end #rect rgb(255, 127, 127) rect rgb(191, 223, 0) Application ->>+ Loader:xrBeginFrame Loader ->>+ Runtime: cmd:IPC_SESSION_BEGIN Runtime -->>- Loader: XRT_SUCCESS Loader -->>- Application: void end #rect rgb(255, 127, 127) rect rgb(191, 223, 0) Application ->>+ Loader:xrEndFrame Loader ->>+ Runtime: cmd:IPC_SESSION_BEGIN Runtime -->>- Loader: XRT_SUCCESS Loader -->>- Application: void end #rect rgb(255, 127, 127)
Frame
Frame的部分,在代码中跟Session是伴生的关系,当Session处于Ready的状态后,就是Frame的调用了。
流程上Frame跟我原本想象的不太一样,他的由wait frame发起,经begin frame,终于end frame。
xrWaitFrame
以代码的角度来追一次整个流程:
Impl Code
Before RPC
- 12345678910111213141516171819202122XrResultoxr_session_frame_wait(struct oxr_logger *log, struct oxr_session *sess, XrFrameState *frameState){......// 1.首先是对`sess->active_wait_frames`做自增,表示有frame可用sess->active_wait_frames++;......// 2.wait semaphore,在一个session中wait frame是单入的os_semaphore_wait(&sess->sem, 0);......// 3. impl with wait frameCALL_CHK(xrt_comp_wait_frame(xc, &sess->frame_id.waited, &predicted_display_time, &predicted_display_period));......// 4. 当session的状态出visible,focus,或者是stopping的时候,return true,第一次进来时为ready,因此return falseframeState->shouldRender = should_render(sess->state);// 5. 根据获取到的period和displaytime做设置frameState->predictedDisplayPeriod = predicted_display_period;frameState->predictedDisplayTime =time_state_monotonic_to_ts_ns(sess->sys->inst->timekeeping, predicted_display_time);......return oxr_session_success_result(sess);}
- 12345678910111213141516171819202122static xrt_result_tipc_compositor_wait_frame(struct xrt_compositor *xc,int64_t *out_frame_id,uint64_t *out_predicted_display_time,uint64_t *out_predicted_display_period){......IPC_CALL_CHK(ipc_call_compositor_predict_frame(icc->ipc_c, // Connectionout_frame_id, // Frame id&wake_up_time_ns, // When we should wake upout_predicted_display_time, // Display timeout_predicted_display_period)); // Current period......// This is how much we should sleep.uint64_t diff_ns = wake_up_time_ns - now_ns;// A minor tweak that helps hit the time better.diff_ns -= measured_scheduler_latency_ns;os_nanosleep(diff_ns);res = ipc_call_compositor_wait_woke(icc->ipc_c, *out_frame_id);......return res;}
In RPC
然后是到了RuntimeServer端:
123456789101112131415161718192021xrt_result_tipc_handle_compositor_predict_frame(volatile struct ipc_client_state *ics,int64_t *out_frame_id,uint64_t *out_wake_up_time_ns,uint64_t *out_predicted_display_time_ns,uint64_t *out_predicted_display_period_ns){......// 1. 在这个函数中会对client session做一个额外的判断,是否是overlay// overlay的sessin visible和focus会被设置为true,其他的具体细节还没有看太明白ipc_server_activate_session(ics);uint64_t gpu_time_ns = 0;return xrt_comp_predict_frame( //ics->xc, //out_frame_id, //out_wake_up_time_ns, //&gpu_time_ns, //out_predicted_display_time_ns, //out_predicted_display_period_ns); //}1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859static inline xrt_result_txrt_comp_predict_frame(struct xrt_compositor *xc,int64_t *out_frame_id,uint64_t *out_wake_time_ns,uint64_t *out_predicted_gpu_time_ns,uint64_t *out_predicted_display_time_ns,uint64_t *out_predicted_display_period_ns){// 1.函数指针的形式跳转return xc->predict_frame( //xc, //out_frame_id, //out_wake_time_ns, //out_predicted_gpu_time_ns, //out_predicted_display_time_ns, //out_predicted_display_period_ns); //}//u_pacing_app.cstatic voidpa_predict(struct u_pacing_app *upa,int64_t *out_frame_id,uint64_t *out_wake_up_time,uint64_t *out_predicted_display_time,uint64_t *out_predicted_display_period){struct pacing_app *pa = pacing_app(upa);//1.记录的是所有wait申请的frame,从0开始,++操作因此返回值从1开始计数int64_t frame_id = ++pa->frame_counter;//2.第一处out返回值:*out_frame_id = frame_id;DEBUG_PRINT_FRAME_ID();//3.这里会去计算cpu运行的时间和绘制的时间,大约会消耗多少nsuint64_t period_ns = calc_period(pa);//4.计算这个frame大概什么时候会显示出来uint64_t predict_ns = predict_display_time(pa, period_ns);//5.Application进程(Client)端需要sleep多久,其实就是未来显示的时间-我们需要做compositor的时间uint64_t wake_up_time_ns = predict_ns - total_app_and_compositor_time_ns(pa);//6.Appliation进程(Client)大约多久以后会再次跟RuntimeServer通信,跟上述的公式不同,其中少了cpu和draw的时间// ??所以compositor是在RuntimeServer做的??uint64_t delivery_time_ns = predict_ns - total_compositor_time_ns(pa);pa->last_returned_ns = predict_ns;*out_wake_up_time = wake_up_time_ns;*out_predicted_display_time = predict_ns;*out_predicted_display_period = period_ns;size_t index = GET_INDEX_FROM_ID(pa, frame_id);assert(pa->frames[index].frame_id == -1);assert(pa->frames[index].state == U_PA_READY);pa->frames[index].state = U_RT_PREDICTED;pa->frames[index].frame_id = frame_id;pa->frames[index].predicted_delivery_time_ns = delivery_time_ns;pa->frames[index].predicted_display_period_ns = period_ns;pa->frames[index].when.predicted_ns = os_monotonic_get_ns();}因此,在一次wait frame之后,我们的
sess->active_wait_frames增加了,同时获取到:- out_wake_up_time,client端需要sleep的时间
- out_predicted_display_time,预计画面显示出来的时间
- out_predicted_display_period,预计消耗多少时间
After RPC
以上是第一次IPC:
ipc_call_compositor_predict_frame的结束,回到Client端的Application进程,继续1234567891011121314151617181920212223static xrt_result_tipc_compositor_wait_frame(struct xrt_compositor *xc,int64_t *out_frame_id,uint64_t *out_predicted_display_time,uint64_t *out_predicted_display_period){......IPC_CALL_CHK(ipc_call_compositor_predict_frame(icc->ipc_c, // Connectionout_frame_id, // Frame id&wake_up_time_ns, // When we should wake upout_predicted_display_time, // Display timeout_predicted_display_period)); // Current period......// 1.从RuntimeServer进程回来后,通过获取到的wake_up_time_ns做sleepuint64_t diff_ns = wake_up_time_ns - now_ns;diff_ns -= measured_scheduler_latency_ns;// 2.sleepos_nanosleep(diff_ns);// 3.继续做一次IPCres = ipc_call_compositor_wait_woke(icc->ipc_c, *out_frame_id);......return res;}我们这边就略过函数指针的部分,直接看函数了:
1234567891011121314151617181920212223242526272829303132333435xrt_result_tipc_handle_compositor_wait_woke(volatile struct ipc_client_state *ics, int64_t frame_id){IPC_TRACE_MARKER();if (ics->xc == NULL) {return XRT_ERROR_IPC_SESSION_NOT_CREATED;}return xrt_comp_mark_frame(ics->xc, frame_id, XRT_COMPOSITOR_FRAME_POINT_WOKE, os_monotonic_get_ns());}static xrt_result_tmulti_compositor_mark_frame(struct xrt_compositor *xc,int64_t frame_id,enum xrt_compositor_frame_point point,uint64_t when_ns){COMP_TRACE_MARKER();struct multi_compositor *mc = multi_compositor(xc);//1.参数为:XRT_COMPOSITOR_FRAME_POINT_WOKEswitch (point) {case XRT_COMPOSITOR_FRAME_POINT_WOKE:os_mutex_lock(&mc->msc->list_and_timing_lock);uint64_t now_ns = os_monotonic_get_ns();//2.实际运行的函数u_pa_mark_point(mc->upa, frame_id, U_TIMING_POINT_WAKE_UP, now_ns);os_mutex_unlock(&mc->msc->list_and_timing_lock);break;default: assert(false);}return XRT_SUCCESS;}123456789101112131415161718192021222324252627static voidpa_mark_point(struct u_pacing_app *upa, int64_t frame_id, enum u_timing_point point, uint64_t when_ns){struct pacing_app *pa = pacing_app(upa);RT_LOG_T("%" PRIi64 " (%u)", frame_id, point);size_t index = GET_INDEX_FROM_ID(pa, frame_id);assert(pa->frames[index].frame_id == frame_id);// 1.point = U_TIMING_POINT_WAKE_UPswitch (point) {case U_TIMING_POINT_WAKE_UP:assert(pa->frames[index].state == U_RT_PREDICTED);pa->frames[index].when.wait_woke_ns = when_ns;pa->frames[index].state = U_RT_WAIT_LEFT;break;case U_TIMING_POINT_BEGIN:assert(pa->frames[index].state == U_RT_WAIT_LEFT);pa->frames[index].when.begin_ns = os_monotonic_get_ns();pa->frames[index].state = U_RT_BEGUN;break;case U_TIMING_POINT_SUBMIT:default: assert(false);}}
最后的这一次:ipc_call_compositor_wait_woke实际是对pacing_app的数据结构做了一次赋值(虽然还是没看太明白)。
结论
整个xrWaitFrame走完,就完成了对XrFrameState的填充:
|
|
xrBeginFrame
Impl Code
Before RPC
- 12345678910111213141516171819202122232425XrResultoxr_session_frame_begin(struct oxr_logger *log, struct oxr_session *sess){......os_mutex_lock(&sess->active_wait_frames_lock);int active_wait_frames = sess->active_wait_frames;os_mutex_unlock(&sess->active_wait_frames_lock);XrResult ret;//1. 如果没有调用wait frame,这边就直接return了if (active_wait_frames == 0) {return oxr_error(log, XR_ERROR_CALL_ORDER_INVALID, "xrBeginFrame without xrWaitFrame");}......//2. 中间有一大段的逻辑是在处理frame叠加的问题,当有超过1个frame时,会做discard处理,这边略过......if (xc != NULL) {CALL_CHK(xrt_comp_begin_frame(xc, sess->frame_id.waited));sess->frame_id.begun = sess->frame_id.waited;sess->frame_id.waited = -1;}os_semaphore_release(&sess->sem);return ret;}
流程上已经很熟练了,这部分就直接来到
ipc_client_XXX1234567891011121314151617181920212223xrt_result_tipc_call_compositor_begin_frame(struct ipc_connection *ipc_c,int64_t frame_id){IPC_TRACE(ipc_c, "Calling compositor_begin_frame");struct ipc_compositor_begin_frame_msg _msg = {.cmd = IPC_COMPOSITOR_BEGIN_FRAME,.frame_id = frame_id,};....// Send our requestxrt_result_t ret = ipc_send(&ipc_c->imc,&_msg,sizeof(_msg));....// Await the replyret = ipc_receive(&ipc_c->imc,&_reply,sizeof(_reply));....return _reply.result;}
In RPC
- 1234567891011xrt_result_tipc_handle_compositor_begin_frame(volatile struct ipc_client_state *ics, int64_t frame_id){IPC_TRACE_MARKER();if (ics->xc == NULL) {return XRT_ERROR_IPC_SESSION_NOT_CREATED;}return xrt_comp_begin_frame(ics->xc, frame_id);}
直接来到:
multi_compositor_begin_frame,这里的流程其实跟wait frame很类似1234567891011121314static xrt_result_tmulti_compositor_begin_frame(struct xrt_compositor *xc, int64_t frame_id){COMP_TRACE_MARKER();struct multi_compositor *mc = multi_compositor(xc);os_mutex_lock(&mc->msc->list_and_timing_lock);uint64_t now_ns = os_monotonic_get_ns();u_pa_mark_point(mc->upa, frame_id, U_TIMING_POINT_BEGIN, now_ns);os_mutex_unlock(&mc->msc->list_and_timing_lock);return XRT_SUCCESS;}- 123456789101112static voidpa_mark_point(struct u_pacing_app *upa, int64_t frame_id, enum u_timing_point point, uint64_t when_ns){......switch (point) {......case U_TIMING_POINT_BEGIN:pa->frames[index].when.begin_ns = os_monotonic_get_ns();pa->frames[index].state = U_RT_BEGUN;break;......}
After RPC
- 123456789101112XrResultoxr_session_frame_begin(struct oxr_logger *log, struct oxr_session *sess){......if (xc != NULL) {CALL_CHK(xrt_comp_begin_frame(xc, sess->frame_id.waited));sess->frame_id.begun = sess->frame_id.waited;sess->frame_id.waited = -1;}......return ret;}
结论
当前session中的
frame_id成员变量的begun改为当前准备使用的frame。pa->frames[index].state = U_RT_BEGUN
xrEndFrame
其实在说EndFrame之前应该要先走一遍Swapchain的流程,因为那个是在做真正意义上的Draw。
Impl Code
不同于waitFrame和beginFrame,endFrame的流程非常复杂。
|
|
因此我们这边有3个函数需要拆解:
xrt_comp_layer_begin(xc, sess->frame_id.begun, display_time_ns, blend_mode)submit_projection_layer(sess, xc, log, (XrCompositionLayerProjection *)layer, xdev, &inv_offset,timestamp)xrt_comp_layer_commit(xc, sess->frame_id.begun, XRT_GRAPHICS_SYNC_HANDLE_INVALID)
xrt_comp_layer_begin
Impl Code
|
|
这里并没有发生ipc,只是做了一些信息记录。
submit_projection_layer
Impl Code
|
|
xrt_comp_layer_stereo_projection
|
|
- wrap了一层以后进入到:
|
|
xrt_comp_layer_commit
Impl Code
Before RPC
|
|
然后是RPC的实现部分,这里的步骤跟之前的不同,所以额外再拿出来,这边有两次IPC。
|
|
In RPC
|
|
- 12345678910111213141516171819202122232425xrt_result_tipc_handle_compositor_layer_sync(volatile struct ipc_client_state *ics,int64_t frame_id,uint32_t slot_id,uint32_t *out_free_slot_id,const xrt_graphics_sync_handle_t *handles,const uint32_t handle_count){......struct ipc_shared_memory *ism = ics->server->ism;struct ipc_layer_slot *slot = &ism->slots[slot_id];......// 1. beginxrt_comp_layer_begin(ics->xc, frame_id, copy.display_time_ns, copy.env_blend_mode);// 2. update_update_layers(ics, ics->xc, ©);// 3. commitxrt_comp_layer_commit(ics->xc, frame_id, sync_handle);// 4. 后处理......*out_free_slot_id = (ics->server->current_slot_index + 1) % IPC_MAX_SLOTS;ics->server->current_slot_index = *out_free_slot_id;......return XRT_SUCCESS;}
begin
1234567891011121314static xrt_result_tmulti_compositor_layer_begin(struct xrt_compositor *xc,int64_t frame_id,uint64_t display_time_ns,enum xrt_blend_mode env_blend_mode){struct multi_compositor *mc = multi_compositor(xc);......mc->progress.active = true;mc->progress.display_time_ns = display_time_ns;mc->progress.env_blend_mode = env_blend_mode;return XRT_SUCCESS;}update
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051static bool_update_layers(volatile struct ipc_client_state *ics, struct xrt_compositor *xc, struct ipc_layer_slot *slot){......for (uint32_t i = 0; i < slot->layer_count; i++) {volatile struct ipc_layer_entry *layer = &slot->layers[i];switch (layer->data.type) {......case XRT_LAYER_STEREO_PROJECTION_DEPTH:if (!_update_projection_layer_depth(xc, ics, layer, i)) {return false;}......}return true;}static bool_update_projection_layer_depth(struct xrt_compositor *xc,volatile struct ipc_client_state *ics,volatile struct ipc_layer_entry *layer,uint32_t i){.......xrt_comp_layer_stereo_projection_depth(xc, xdev, l_xcs, r_xcs, l_d_xcs, r_d_xcs, data);return true;}static xrt_result_tmulti_compositor_layer_stereo_projection_depth(struct xrt_compositor *xc,struct xrt_device *xdev,struct xrt_swapchain *l_xsc,struct xrt_swapchain *r_xsc,struct xrt_swapchain *l_d_xsc,struct xrt_swapchain *r_d_xsc,const struct xrt_layer_data *data){struct multi_compositor *mc = multi_compositor(xc);size_t index = mc->progress.layer_count++;mc->progress.layers[index].xdev = xdev;xrt_swapchain_reference(&mc->progress.layers[index].xscs[0], l_xsc);xrt_swapchain_reference(&mc->progress.layers[index].xscs[1], r_xsc);xrt_swapchain_reference(&mc->progress.layers[index].xscs[2], l_d_xsc);xrt_swapchain_reference(&mc->progress.layers[index].xscs[3], r_d_xsc);mc->progress.layers[index].data = *data;return XRT_SUCCESS;}submit
12345678910111213141516171819202122232425262728293031323334353637static xrt_result_tmulti_compositor_layer_commit(struct xrt_compositor *xc, int64_t frame_id, xrt_graphics_sync_handle_t sync_handle){.......do {......// 1. import fencexrt_result_t xret = xrt_comp_import_fence( //&mc->msc->xcn->base, //sync_handle, //&xcf); ///*!* If import_fence succeeded, we have transferred ownership to* the compositor no need to do anything more. If the call* failed we need to close the handle.*/if (xret == XRT_SUCCESS) {break;}u_graphics_sync_unref(&sync_handle);} while (false); // Goto without the labels.if (xcf != NULL) {//2. wait fencewait_fence(&xcf);}//3.wait for schedulewait_for_scheduled_free(mc);os_mutex_lock(&mc->msc->list_and_timing_lock);//4. deliveredu_pa_mark_delivered(mc->upa, frame_id);os_mutex_unlock(&mc->msc->list_and_timing_lock);return XRT_SUCCESS;}import fence
- 这里是直接走到了comp_base,这部分的函数确实没有看懂,不过猜测就是构建函数指针,后面会用
12345678910111213141516171819202122xrt_result_tcomp_fence_import(struct vk_bundle *vk, xrt_graphics_sync_handle_t handle, struct xrt_compositor_fence **out_xcf){COMP_TRACE_MARKER();VkFence fence = VK_NULL_HANDLE;VkResult ret = vk_create_fence_sync_from_native(vk, handle, &fence);if (ret != VK_SUCCESS) {return XRT_ERROR_VULKAN;}struct fence *f = U_TYPED_CALLOC(struct fence);f->base.wait = fence_wait;f->base.destroy = fence_destroy;f->fence = fence;f->vk = vk;*out_xcf = &f->base;return XRT_SUCCESS;}wait_fence,基本就是调用刚才import的函数做事,这地方的fence就会跟Multi-Compositor-Thread中的流程对应起来,在做
compositor_layer_commit的时候就会触发了。1234567static voidwait_fence(struct xrt_compositor_fence **xcf_ptr){COMP_TRACE_MARKER();xrt_compositor_fence_wait(*xcf_ptr, UINT64_MAX);xrt_compositor_fence_destroy(xcf_ptr);}delivered
12345678910static voidpa_mark_delivered(struct u_pacing_app *upa, int64_t frame_id){......f->when.delivered_ns = now_ns;......f->state = U_PA_READY;f->frame_id = -1;......}
结论
从目前整个调用流程来看,xrEndFrame会把所有已经在Application端绘制好的内容交给RuntimeServer中的Multi-Compositor-Thread。
其中的细节部分就需要去看Swapchain的内容了。
Compositor-Thread
Compositor的线程是运行在RuntimeServer进程的,拉起的时间点是comp_multi_create_system_compositor
这个在Session-xrCreateSession-In RPC章节的时候有提到,在
XrCreateSession中会跑到123456789101112xrt_result_tcomp_multi_create_system_compositor(struct xrt_compositor_native *xcn,const struct xrt_system_compositor_info *xsci,struct xrt_system_compositor **out_xsysc){struct multi_system_compositor *msc = U_TYPED_CALLOC(struct multi_system_compositor);......msc->xcn = xcn;os_thread_helper_start(&msc->oth, thread_func, msc);......return XRT_SUCCESS;}这里的
xcn可以溯源一下,其实是上层调用函数:xrt_gfx_provider_create_system中创建的并赋值的:&c->base.base123456789101112131415161718192021222324voidcomp_base_init(struct comp_base *cb){......cb->base.base.create_swapchain = base_create_swapchain;cb->base.base.import_swapchain = base_import_swapchain;cb->base.base.import_fence = base_import_fence;cb->base.base.layer_begin = base_layer_begin;cb->base.base.layer_stereo_projection = base_layer_stereo_projection;cb->base.base.layer_stereo_projection_depth = base_layer_stereo_projection_depth;......}xrt_result_txrt_gfx_provider_create_system(struct xrt_device *xdev, struct xrt_system_compositor **out_xsysc){struct comp_compositor *c = U_TYPED_CALLOC(struct comp_compositor);c->base.base.base.begin_session = compositor_begin_session;c->base.base.base.end_session = compositor_end_session;......comp_base_init(&c->base);return comp_multi_create_system_compositor(&c->base.base, sys_info, out_xsysc);}因此直接给到thread的参数为:
struct multi_system_compositor *msc,其中msc->xcn=&c->base.base其中函数指针的填充是由:
xrt_gfx_provider_create_system和comp_base_init共同完成的。部分实现是落在
comp_base.c中的
thread主体部分,流程上:
- begin session
- 进入循环
- wait frame
- begin frame
- layer begin
- layer locked
- layer commit
- End session
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051xrt/compositor/multi/comp_multi_system.cstatic void *thread_func(void *ptr){return (void *)(intptr_t)multi_main_loop((struct multi_system_compositor *)ptr);}static intmulti_main_loop(struct multi_system_compositor *msc){COMP_TRACE_MARKER();struct xrt_compositor *xc = &msc->xcn->base;//! @todo Don't make this a hack.enum xrt_view_type view_type = XRT_VIEW_TYPE_STEREO;xrt_comp_begin_session(xc, view_type);os_thread_helper_lock(&msc->oth);while (os_thread_helper_is_running_locked(&msc->oth)) {os_thread_helper_unlock(&msc->oth);......wait_frame( //xc, //&frame_id, //&wake_time_ns, //&predicted_gpu_time_ns, //&predicted_display_time_ns, //&predicted_display_period_ns); //............xrt_comp_begin_frame(xc, frame_id);xrt_comp_layer_begin(xc, frame_id, 0, 0);// Make sure that the clients doesn't go away while we transfer layers.os_mutex_lock(&msc->list_and_timing_lock);transfer_layers_locked(msc, predicted_display_time_ns);os_mutex_unlock(&msc->list_and_timing_lock);xrt_comp_layer_commit(xc, frame_id, XRT_GRAPHICS_SYNC_HANDLE_INVALID);// Re-lock the thread for check in while statement.os_thread_helper_lock(&msc->oth);}xrt_comp_end_session(xc);return 0;}
拆解一下各个函数具体在做什么,就可以了解到整个Compositor线程的职责了。在这之前,我们先明确:
struct xrt_compositor *xc = &msc->xcn->base;这个指针实际的对象地址因此直接给到thread的参数为:
struct multi_system_compositor *msc,其中msc->xcn=&c->base.base实际的指针地址为
xrt_gfx_provider_create_system函数中创建struct comp_compositor *c的成员变量c->base.base1234567891011121314xrt_gfx_provider_create_system(struct xrt_device *xdev, struct xrt_system_compositor **out_xsysc){struct comp_compositor *c = U_TYPED_CALLOC(struct comp_compositor);c->base.base.base.begin_session = compositor_begin_session;c->base.base.base.end_session = compositor_end_session;c->base.base.base.predict_frame = compositor_predict_frame;c->base.base.base.mark_frame = compositor_mark_frame;c->base.base.base.begin_frame = compositor_begin_frame;c->base.base.base.discard_frame = compositor_discard_frame;c->base.base.base.layer_commit = compositor_layer_commit;c->base.base.base.poll_events = compositor_poll_events;c->base.base.base.destroy = compositor_destroy;......}有了这个理解之后,后续所有的函数调用就好找了。
(TODO:Furture)
Furture TODO
Swapchain
- xrCreateSwapchain
- xrDestroySwapchain
- xrAcquireSwapchainImage
- xrReleaseSwapchainImage
- xrWaitSwapchainImage
ShareMemory
- RPC with Draw