结论
一张图,先放结论再说过程吧,图解说明如下:
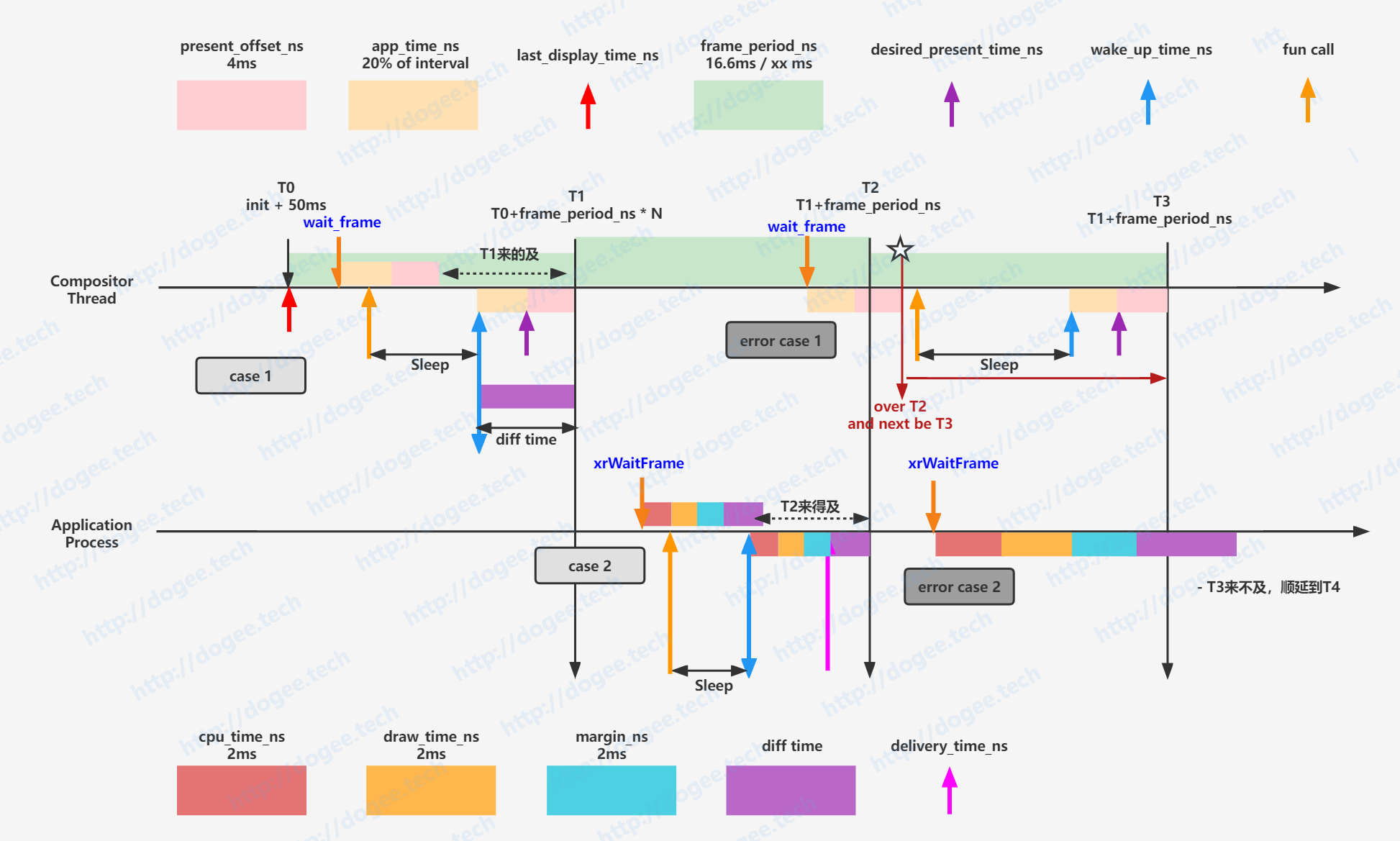
- case 1:
- 首先是发起
wait_frame,其中会综合考量present_offset_ns + app_time_ns + now是否超过了T1的时间点 - 在不超过的情况下,会修改
predicted_display_time_ns为T1的时间点 - 从
predictted_display_time_ns减去present_offset_ns + app_time_ns,得到的值就是最迟需要开始做的时间点 - 当
wait_frame完成以后,需要根据上面计算出来的时刻做sleep
- 首先是发起
- case 2:
- Client端会发起
xrWaitFrame的动作,这个动作可能发生在任意时刻。 - Client端在尝试获取
predicted_display_time_ns的时候,会计算- Client端本身cpu的耗时(逻辑业务)
- Client端本身gpu渲染的耗时
- 额外的一些开销(margin)
- 上一次Compositor Thread做Compose(合成)的时候花费了多少时间
- 在综合考虑了以上因素后,才会得到Client端的
predicted_display_time_ns - 另外由于Compositor的部分是在Runtime进程做的,因此还会有一个
delivery_time_ns,也就是在这个时刻Client必须要发送数据给到Runtime了
- Client端会发起
- error case 1和error case 2:
- 这两个case其实都是出现问题的情况了,都是往后顺延一个
帧间间隔
- 这两个case其实都是出现问题的情况了,都是往后顺延一个
综合来看,其实有几个时间是存在tuning的:
- Compositor Thread:
present_offset_ns:现在来看有点类似于runtime端gpu需要运行的时间,Monado的代码设置的经验值为4msapp_time_ns:runtime端cpu需要运行的时间,目前设置的时间为整个帧间间隔的20%
- Client端(Application进程)
cpu_time_ns:经验值2msdraw_time_ns:经验值2msmargin_ns:经验值2msdiff time:这个值其实是从Compositor Thread那边拿到的,主要是估算整个Compositor的时间,因此app的内容需要视这个时间来做delivery。
xrWaitFrame
在timing的使用中,一切的起源就是xrWaitFrame,其实这个部分在spec上是有着一大段定义的。
Spec of xrWaitFrame
https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#xrWaitFrame
xrWaitFrame throttles the application frame loop in order to synchronize application frame submissions with the display.
- 这一段只是介绍函数的功能,它是用来控制application提交节奏的。
xrWaitFrame returns a predicted display time for the next time that the runtime predicts a composited frame will be displayed. The runtime may affect this computation by changing the return values and throttling of xrWaitFrame in response to feedback from frame submission and completion times in xrEndFrame.
- 这一段有几个信息:
xrWaitFrame会返回一个预测的显示时间(predicted display time),这个是一个未来的时间,也就是下一次合成后的图片什么时候会显示。- 这个返回的时间会收到上一次
xrEndFrame的影响
An application must eventually match each xrWaitFrame call with one call to xrBeginFrame. A subsequent xrWaitFrame call must block until the previous frame has been begun with xrBeginFrame and must unblock independently of the corresponding call to xrEndFrame.
- 这个也没什么特别的,针对
xrWaitFrame,xrBeginFrame,xrEndFrame的一个调用顺序的说明
When less than one frame interval has passed since the previous return from xrWaitFrame, the runtime should block until the beginning of the next frame interval.If more than one frame interval has passed since the last return from xrWaitFrame, the runtime may return immediately or block until the beginning of the next frame interval.
- 如果两次
xrWaitFrame的时间间隔小于一帧,那么整个调用就要被block住,直到下一个帧开始的时候才会返回回来,这个是一个有很意思的点。代码实现中就是通过sleep来解决的,至于说如果两次xrWaitFrame大于了一帧的间隔,那么就看情况而定了。
In the case that an application has pipelined frame submissions, the application should compute the appropriate target display time using both the predicted display time and predicted display interval. The application should use the computed target display time when requesting space and view locations for rendering.
- 因此,对于应用来说,应用需要获得未来的上屏时间
predicted display time和显示的帧间隔predicted display interval,从而使用预测的这个时间去跟OpenXR要space & view的数据,从而完成应用端的渲染,也就是实际应用未来的画面应该是什么样。
The XrFrameState::
predictedDisplayTimereturned by xrWaitFrame must be monotonically increasing.
- 时间是单调递增的,实际代码中
clock_gettime(CLOCK_MONOTONIC, &ts);,也就是从系统开机开始的时间
The runtime may dynamically adjust the start time of the frame interval relative to the display hardware’s refresh cycle to minimize graphics processor contention between the application and the compositor.
- 帧率是可调的,所以帧间隔也是会变的,runtime的部分是要动态调整的。
xrWaitFrame must be callable from any thread, including a different thread than xrBeginFrame/xrEndFrame are being called from.
Calling xrWaitFrame must be externally synchronized by the application, concurrent calls may result in undefined behavior.
The runtime must return
XR_ERROR_SESSION_NOT_RUNNINGif thesessionis not running.
- 这一段也没什么可以额外说的,无非就是线程无关,外部同步。
总结一下,xrWaitFrame其实是给出未来的上屏时间predicted display time和显示的帧间隔predicted display interval。
Out Params:XrFrameState
那么这两个参数是怎么得到的,根据Spec的定义,其实是从XrFrameState拿到的,继续看Spec中关于XrFrameState的说明:
XrFrameState describes the time at which the next frame will be displayed to the user.
predictedDisplayTimemust refer to the midpoint of the interval during which the frame is displayed. The runtime may report a differentpredictedDisplayPeriodfrom the hardware’s refresh cycle.
predictedDisplayTime是整个帧在显示过程中的中点位置的时间。predictedDisplayPeriod需要根据硬件的刷新率改变而改变。
For any frame where
shouldRenderisXR_FALSE, the application should avoid heavy GPU work for that frame, for example by not rendering its layers. This typically happens when the application is transitioning into or out of a running session, or when some system UI is fully covering the application at the moment. As long as the session is running, the application should keep running the frame loop to maintain the frame synchronization to the runtime, even if this requires calling xrEndFrame with all layers omitted.
- 解释了
shouldRender的作用,不做展开了
代码实现
Overview
先上图,再整码,整个Compositor其实是比较绕的一个套逻辑,希望这篇文章可以讲明白其中的道道。
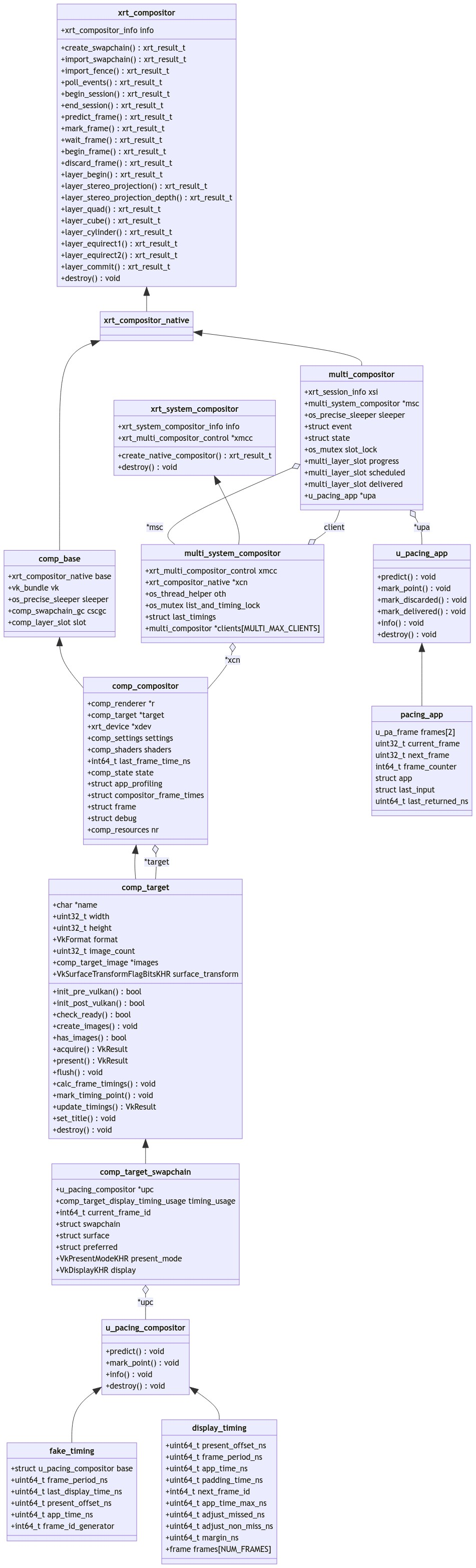
几种数据结构
Monado方案下的数据结构比较绕,主要是分为两块:
- 应用程序进程中,也就是Client的:
multi_compositoru_pacing_app
- Runtime进程中,Compositor Thread的:
multi_system_compositorcomp_compositordisplay_timing- fake_timing
其中multi_compositor和comp_compositor都是属于xrt_compositor_native的子类,所以它们其实是根正苗红的compositor
而multi_systemcompositor其实是xrt_system_compositor的子类,其实并不是做compositor的事情。
所以我们需要明白,在Client端实际负责各种xrWaitFrame等等动作的,最终是跑到multi_compositor上,而在Compositor Thread上真正工作的是comp_compositor。
Compositor Thread
整个代码的入口,我选择从Compositor Thread开始,其中的原因是因为Compositor Thread的初始化是比较早的,这个在《Monaod Out Of Process》流程分析中其实已经有说到了,这边就不在做展开了(nativeStartServer):
初始化
在Compositor Thread中,我们用到的数据结构为:multi_system_compositor,其中初始化的部分:
|
|
其中有4个参数需要关注一下:
msc->xcn是传入的参数struct xrt_compositor_native *xcn,它是谁?- 初始化的三个参数:
msc->last_timings.predicted_display_time_ns = os_monotonic_get_ns();,直接为当前时间msc->last_timings.predicted_display_period_ns = U_TIME_1MS_IN_NS * 16;,假定当前的显示周期为16毫秒msc->last_timings.diff_ns = U_TIME_1MS_IN_NS * 5;,这个diff时间为5毫秒
带着第一个问题,struct xrt_compositor_native *xcn它是谁,我们看一下调用方:
|
|
- 所以结论:
msc->xcn实际是:comp_compositor
更新流程
整个Compositor thread的工作流程,还是非常清晰的。
|
|
由于我们关注点是timing的更新,可以看到在Compositor Thread中这个部分其实就是wait_frame的工作,继续结合代码往下走:
|
|
在继续深挖一下,xrt_comp_predict_frame是一个monado中常见的 wrap手段:
|
|
所以实际调用的:compositor_predict_frame:
|
|
其中comp_target_calc_frame_timings的调用又是一个wrap的封装:
|
|
所以,实际就是调用到了:comp_target_swapchain_calc_frame_timings:
真正的计算
|
|
层层封装,u_pc_predict还是一个wrap:
|
|
运行到这里,什么都还没开始呢,我们重新来整理一下整个流程。
- Compositor Thread中发起了一次
wait_frame - 接着是调用到了
comp_compositor::predict_frame,实际函数:compositor_predict_frame - 接着是调用到了
comp_target::calc_frame_timings,实际函数:comp_target_swapchain_calc_frame_timings - 最后是调用到了
u_pacing_compositor::predict,实际函数是:pc_predict
|
|
最终的实现时,又是调用的predict_next_frame
|
|
我们在结合一下初始化fake_timing初始化的地方:
|
|
好了,这边就是拆解到底了,我们再反过来看看整个计算的过程。
|
|
获取到了predict_next_frame的时间,那么再来看其他的参数:
|
|
中间省略掉一些by pass的过程,我们直接到compositor_predict_frame,其中out_min_display_period_ns,out_predicted_display_period_ns在半路就被丢弃了。
|
|
继续回溯:
|
|
带着以上的信息,回到Compositor Thread的主循环中:
|
|
下面的部分就简单了:
|
|
再去看其中wrap的函数u_pa_info,是一个空实现:
|
|
以上就是Compositor Thread端做更新的一个流程了,后续其实就是在循环中不断迭代着。
Client端
Client端的流程实际跟Compositor Thread差不多。
初始化
Client端的数据结构之前也介绍过了:
multi_compositoru_pacing_app
有了之前的经验,其实在Client端我们就看两个地方,就是上面这两个数据结构的初始化:
|
|
我们先看一下u_pa_create
|
|
然后是u_pa_info,很自然这个又是一个wrap函数,真实的函数未:pa_info
|
|
更新流程
带着这些信息,我看再来看xrWaitFrame的返回,wrap的部分我们都直接略过了,这个部分可以参考《Loader & Broker》以及《Out Of Process》两篇文档,我们直接来到oxr_xrWaitFrame:
|
|
然后这个xrt_comp_wait_frame其实还是一个wrap,实际的函数:ipc_compositor_wait_frame
|
|
然后看ipc_call_compositor_predict_frame,我们直接看Server端吧:ipc_handle_compositor_predict_frame
|
|
一模一样的,xrt_comp_predict_frame依旧是个wrap,实际的函数为:multi_compositor_predict_frame
真正的计算
|
|
u_pa_predict还是一个wrap,实际的函数为:pa_predict
|
|
所以,我们展开这个函数看一看,就可以得出最后的结论了:
uint64_t period_ns = calc_period(pa);
|
|
uint64_t predict_ns = predict_display_time(pa, period_ns);
|
|
uint64_t wake_up_time_ns = predict_ns - total_app_and_compositor_time_ns(pa);- 这里的
wake_up_time_ns跟Compositor Thread的意思其实是一样的,就是app可以先等到这个时刻,再开始做事。
- 这里的
uint64_t delivery_time_ns = predict_ns - total_compositor_time_ns(pa);delivery_time_ns其实也好理解,就是app最晚在什么时候,需要把render的动作做完,并告知Server。
|
|
其实到这里,整个Client端的时间计算也就结束了,一个小的注意点是,pa的部分会存储前一帧的数据。
|
|
然后带着:
- out_wake_up_time
- out_predicted_display_time
- out_predicted_display_period
再看看RPC的后半段:
|
|
TODO
[ ] 由于在实际代码中Monado使用的
fake_timing,另外还有一套display_timing,这套会跟Vulkan的一些api有关[ ] has_GOOGLE_display_timing
[ ] 实际QCOM XR2平台下,OpenXR中的一些Timing是怎么样的
[ ] ATW中是否有Timing相关的任务?