前情提要
这一篇文章是针对《model_personalization》项目的一个代码解读。
https://github.com/tensorflow/examples/tree/8ad788d9c78fb914d4c768ad19beb552ca3ae6fc/lite/examples/model_personalization
代码解读分为四个步骤:
- tflite预准备:5个tflite模型文件
- 模型加载初始化:Android端如何加载模型文件
- 模型参数的训练:Android端的训练过程,epoch,batch
- 模型应用以及识别:inference的过程
tflite预准备
迁移学习
整个model_personalization的思路,其实是用到了迁移学习(transfer learning),一句话来解释:
“用已经在其他数据集上训练的比较好的模型,通过训练最后输出节点的方式来训练一个新模型,使得它可以较快的收敛并较好的识别新的分类任务。“
针对model_personalization的说明,Google也有一篇文章做了针对这个项目的简单说明。其中《What is transfer learning?》这个章节的图比较有说明意义: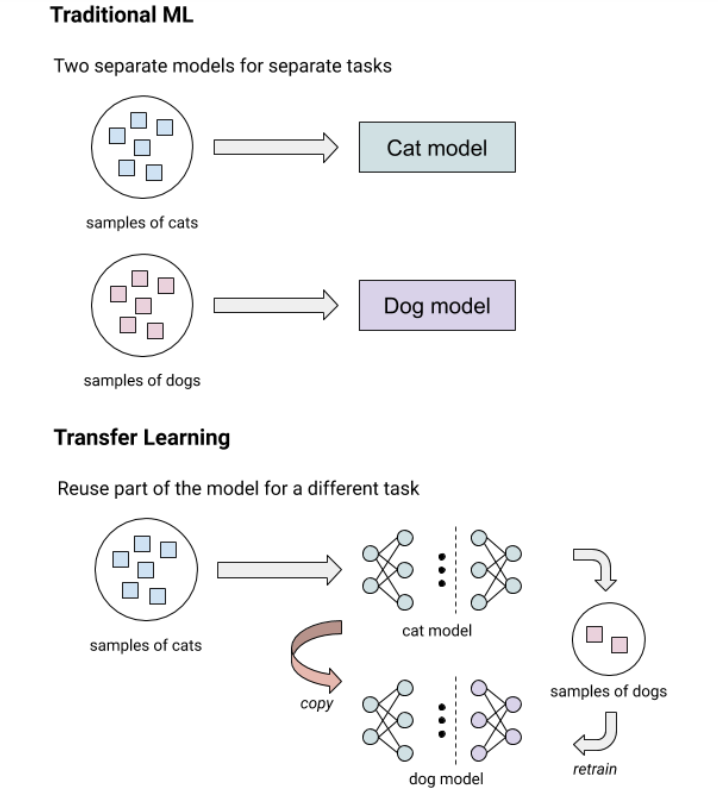
5个tflite
言归正传,正因为迁移学习有着“数据少,收敛快,识别率好”的特性,所以大牛就想办法弄到手机上来做成personalization,针对这个情况,在工程化的道路上需要用到5个tflite,它们分别是:
- bottleneck.tflite,已经训练完的网络结构,目的是获取最底下的那一层特征提取层的结果。
- input: input_1: [1,224,224,3] 图片数据输入
- output: Identity:[1,7,7,1280] 特征输出
- initialize.tflite,初始化参数的网络
- input: zero
- output: Identity [62720,4] weight参数
- output: Identity_1 [4] bias参数
- train_head.tflite,训练网络
- input:placeholder_bottleneck:[20,7,7,1280] 主要是由bottleneck计算出来的
- input:placeholder_ws: [62720,4] 由initialize初始化的训练参数
- input:placeholder_bs: [4] 由initialize初始化的训练参数
- input:placeholder_labels: [20,4] one_hot的label数据
- output:head/loss/add: loss
- output:head/backprop/add:[62720,4] weight梯度
- output:head/backprop/Mean:[4] add梯度
- optimizer.tflite,参数更新网络
- input:Placeholder:[62720,4] 当前weight参数
- input:Placeholder_2:[62720,4] 计算到的weight梯度
- input:Placeholder_1:[4] 当前bias参数
- input:Placeholder_3:[4] 计算到的bias梯度
- output:sub: [62720,4] 计算后的weight参数
- output:sub_1:[4] 计算后的bias参数
- inference.tflite,推演/识别网络
- input:placeholder_bottleneck:[20,7,7,1280] 主要是由bottleneck计算出来的
- input:placeholder_ws: [62720,4] 由initialize初始化的训练参数
- input:placeholder_bs: [4] 由initialize初始化的训练参数
- output:Softmax:[1,4] 各个分类的结果
在机器学习中,一般网络的组成是分为input数据,主干网络,optimizer算子,在训练的过程中,不断从整体数据(epoch)中获取batch,然后送去主干网络,获得计算的结果output,通过output与真实值groundtruth的loss,选取合适的optimizer算子做反向传播,对参数做更新,然后进行第二轮的batch迭代,直到loss不断变小收敛,获得一个较好的模型,训练才会停止。
停止训练后,我们会把训练过程中的获得的参数固化,从而把主干网络变成inference model,也就是推演模型,利用这个模型在实际使用中对待识别物体进行识别。
在迁移学习中(本项目中),针对上述5类模型,我们做出如下分类:
- input数据:initialize.tflite,bottleneck.tflite
- 主干网络:train_head.tflite
- optimizer算子:optimizer.tflite + (部分train_head.tflite)
- 推演模型:inference.tflite
带着这些问题,我们去看一下具体的代码。
模型加载初始化
我们先来看一张类图,其中5个关键类对应了上面的5个tflite。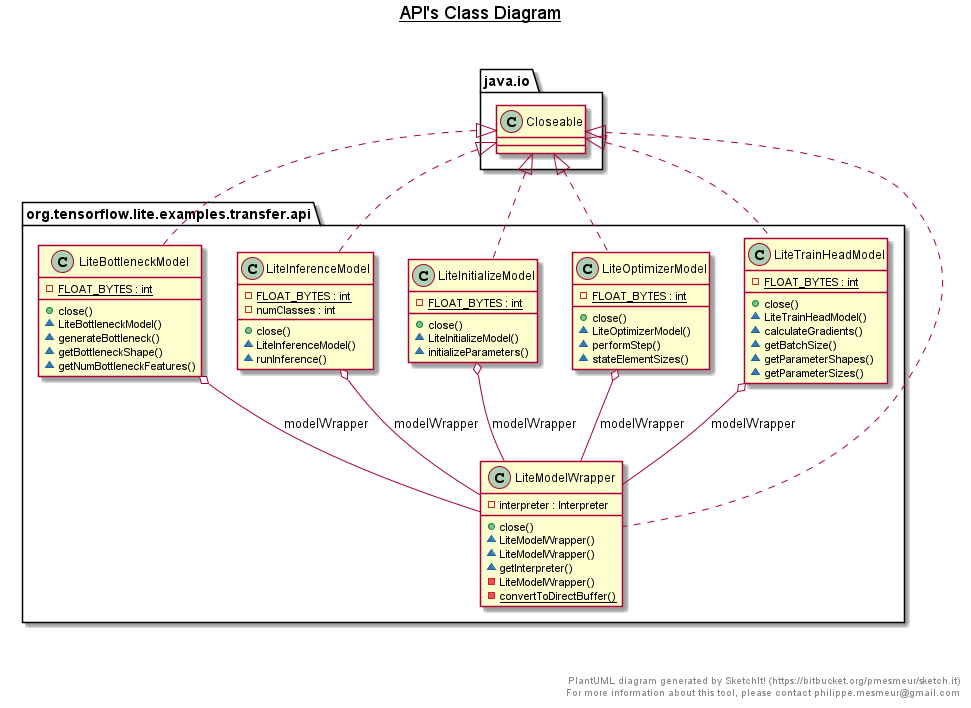
可以看到每个类都有它独特的任务,如:
- LiteBottleneckModel::generateBottleneck
- LiteTrainHeadModel::calculateGradients
- LiteOptimizerModel::performStep
- LiteInferenceModel::runInference
把这些Model都串联起来的,是TransferLearningModel这个类。
我们直接看一下这个类的初始化构造函数。
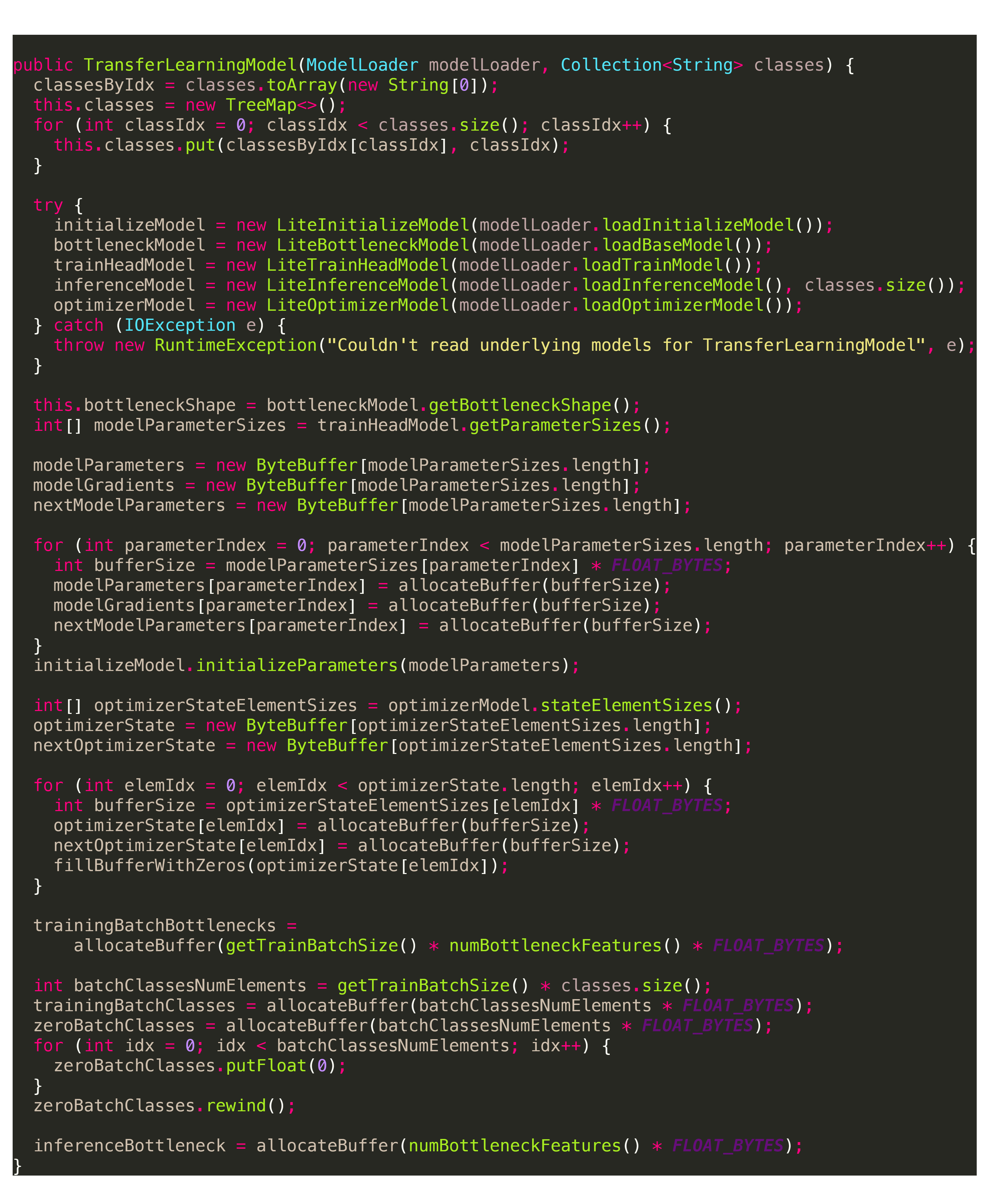
在这里,可以明显看到整个初始化阶段其实是分为两段的:
- Model对象实例化
- TransferLearningModel重要成员变量的初始化
第一个阶段,Model对象实例化
这个阶段,其实就是new各类LiteXXXModel。
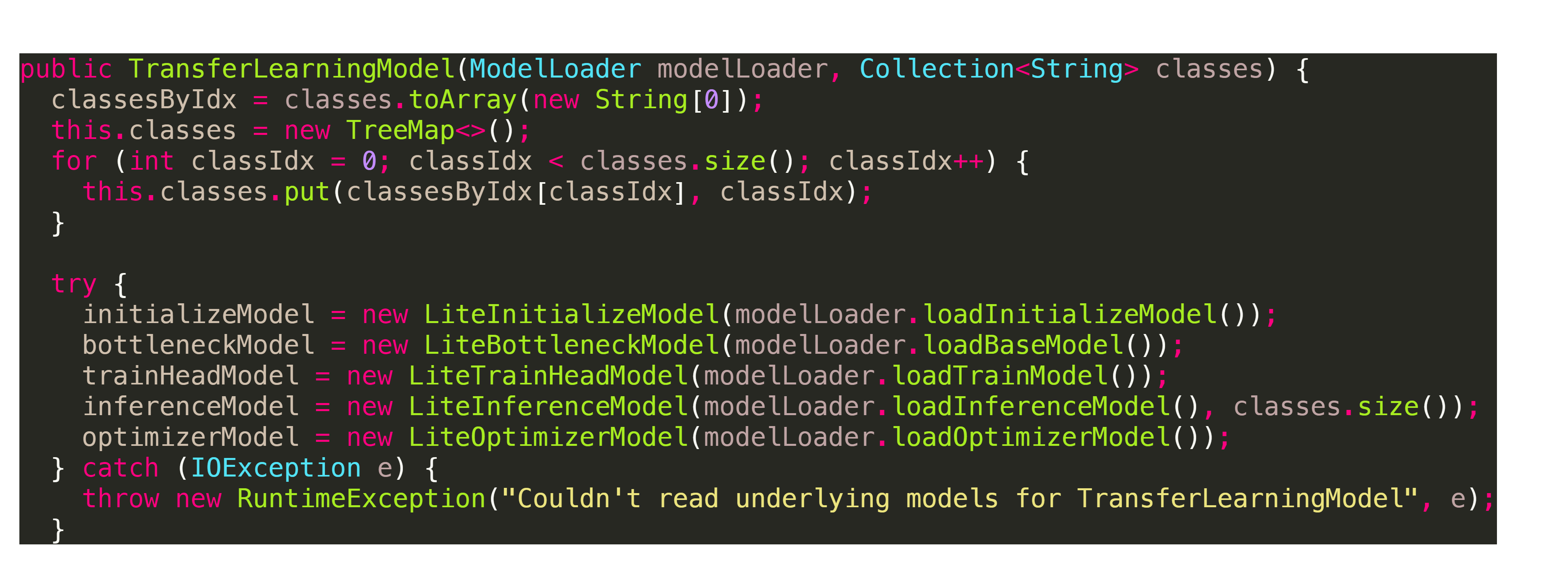
整个过程其实就是把AssetsManager的ModelWrapper传给具体的LiteXXXXModel,这里就不做展开了。
第二个阶段,初始化重要的成员变量
这个阶段是能否可以理解整套代码的关键。
在这里会涉及TransferLearningModel的成员变量有:
- bottleneckShape:
private final int[] bottleneckShape; - modelParameters:
private ByteBuffer[] modelParameters; - modelGradients:
private final ByteBuffer[] modelGradients; - nextModelParameters:
private ByteBuffer[] nextModelParameters; - optimizerState:
private ByteBuffer[] optimizerState; - nextOptimizerState:
private ByteBuffer[] nextOptimizerState; - trainingBatchBottlenecks:
private final ByteBuffer trainingBatchBottlenecks; - trainingBatchClasses:
private final ByteBuffer trainingBatchClasses; - zeroBatchClasses:
private final ByteBuffer zeroBatchClasses; - inferenceBottleneck:
private ByteBuffer inferenceBottleneck;
一共有10个变量,我们从上到下把这10个变量的初始化过程弄明白。
bottleneckShape
Shape代表了形状的意思,在这里其实是bottlenect的维度。
获取的地方是从bottlenectModel,其实也就是bottlenect.tflite。
调用代码:onCall

实现代码:onImpl

tflite模型图示:
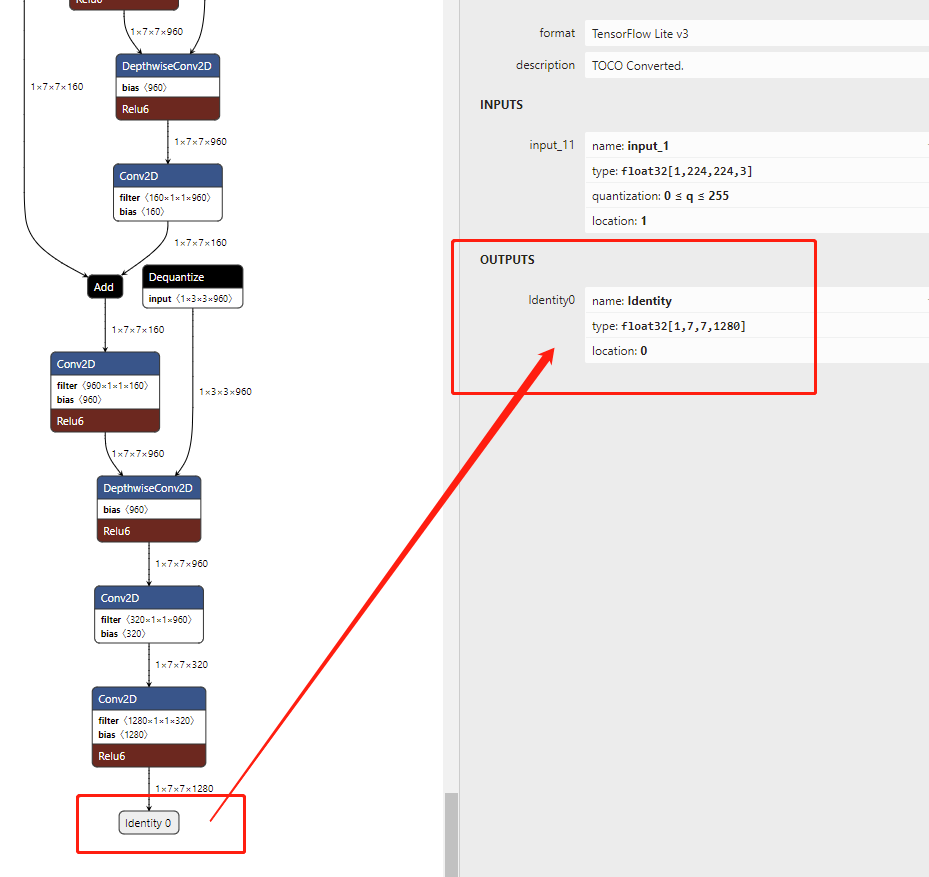
代码解析
我们最终获取的是bottlenect.tflite中output的shape,这边对应是[1,7,7,1280,实际运行中也是这样: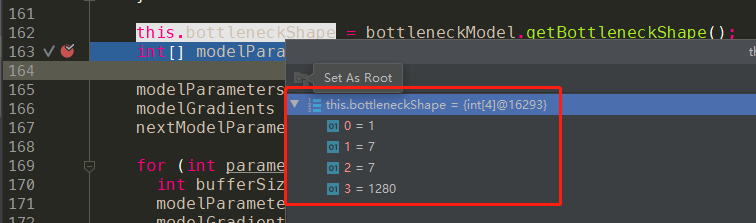
因此:int[] bottleneckShape = [1,7,7,1280]
modelParameters,modelGradients,nextModelParameters
这三个变量的初始化过程是在一起的,所以放在一起讲了。
这些变量的初始化地方是从trainHeadModel,所以就跟trainHead.tflite有联系了。对于trainHead模型来说,其中的参数是迁移学习训练出来的,所以这部分的参数,其实就是在训练中需要通过反向传播去不断更新的。
调用代码:onCall
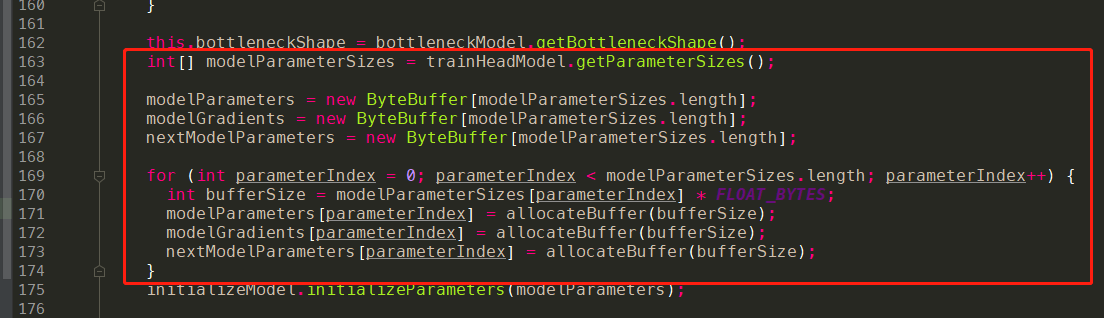
实现代码:onImpl
tflite模型图示:
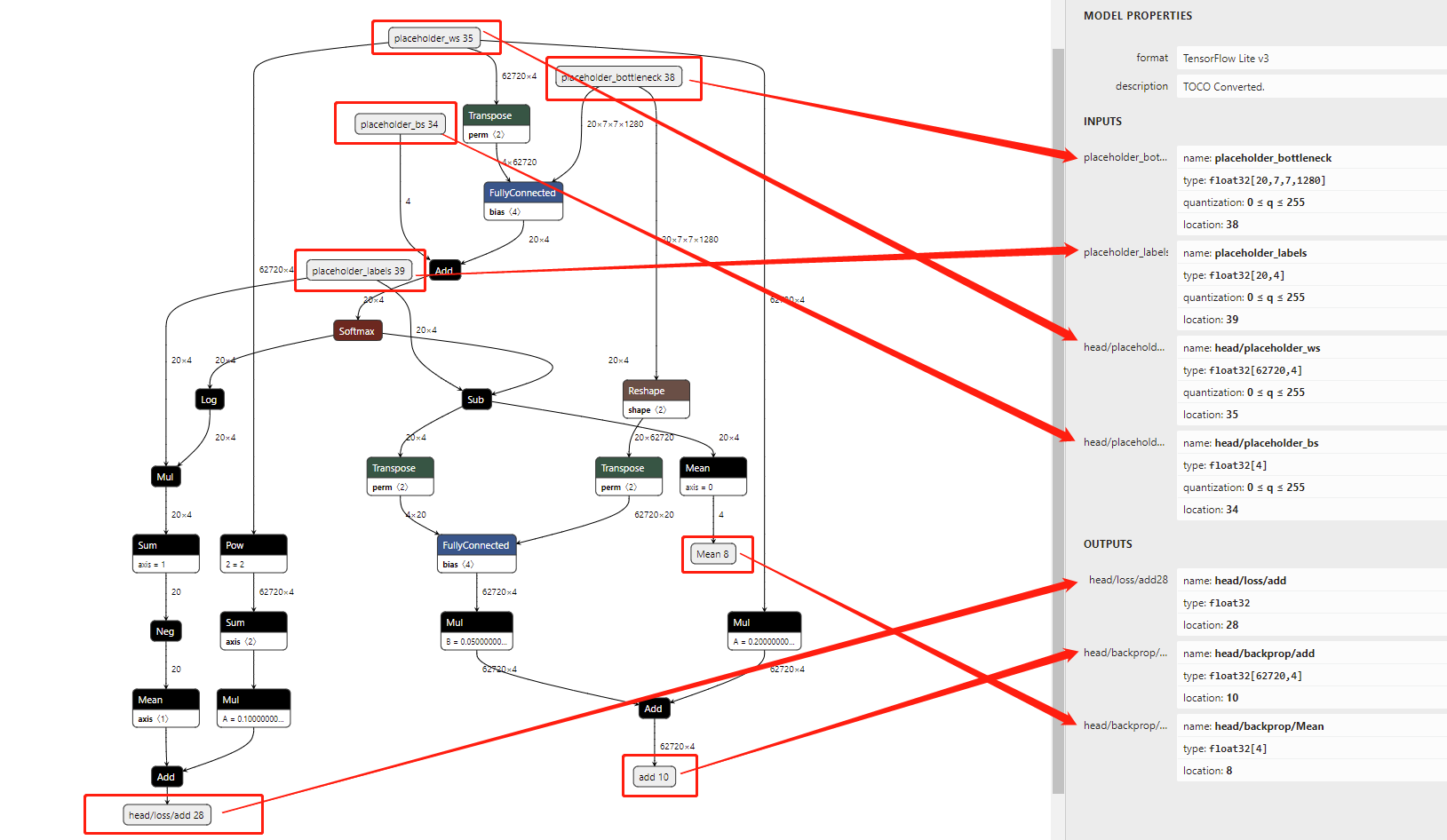
代码解析:
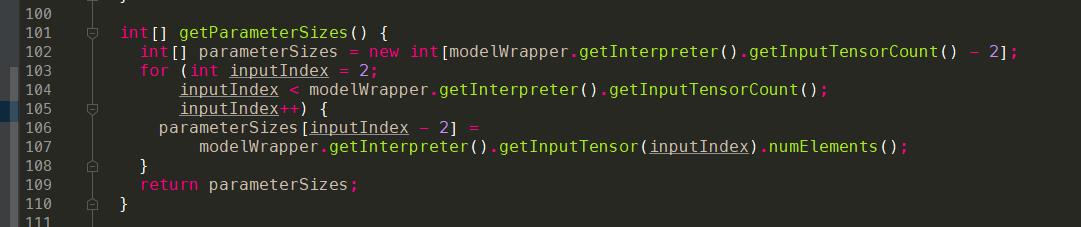
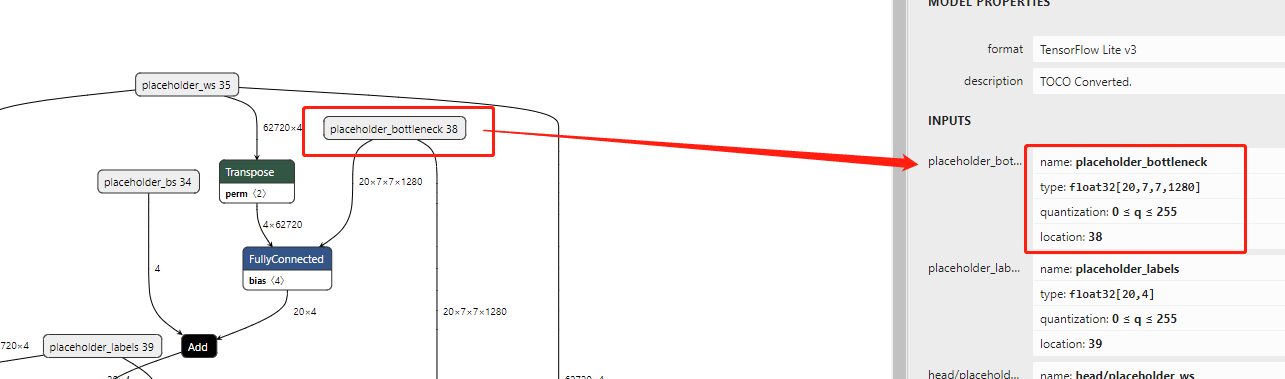
从tflite的模型图示,我们可以看到trainHead.tflite有4个input节点以及3个output节点。
input的四个节点分别为:- placeholder_bottleneck:[20,7,7,1280]
- placeholder_labels:[20,4]
- head/placeholder_ws:[62720,4]
- head/placeholder_bs:4
从代码中,我们可以看到确实有4个index,顺序跟tflite使用netron的图恰好是一样的,目前这个顺序无法确定是否永远跟netron的一致,可能是跟模型转化有关。
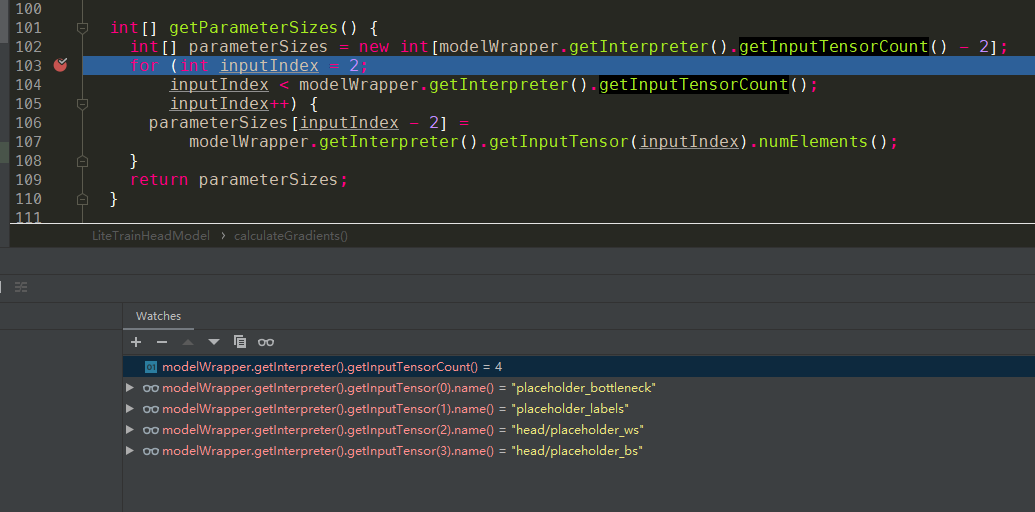
其中:- modelWrapper.getInterpreter().getInputTensor(0).name() = “placeholder_bottleneck”
- modelWrapper.getInterpreter().getInputTensor(1).name() = “placeholder_labels”
- modelWrapper.getInterpreter().getInputTensor(2).name() = “head/placeholder_ws”
- modelWrapper.getInterpreter().getInputTensor(3).name() = “head/placeholder_bs”
根据代码,我们可以得出:
int[] parameterSizes = new int[2]1234// "head/placeholder_ws"parameterSizes[0] = modelWrapper.getInterpreter().getInputTensor(2).numElements();// "head/placeholder_bs"parameterSizes[1] = modelWrapper.getInterpreter().getInputTensor(3).numElements();实际上就是后两个input的参数,其中
numElements是shapes的乘积,回到tflite的图。- head/placeholder_ws:[62720,4]
- head/placeholder_bs:[4]
因此:
12parameterSizes[0] = 62720 x 4 = 250880parameterSizes[1] = 4由于我们每个元素是
float32的类型,而Byte和float32的转换比例是1:4。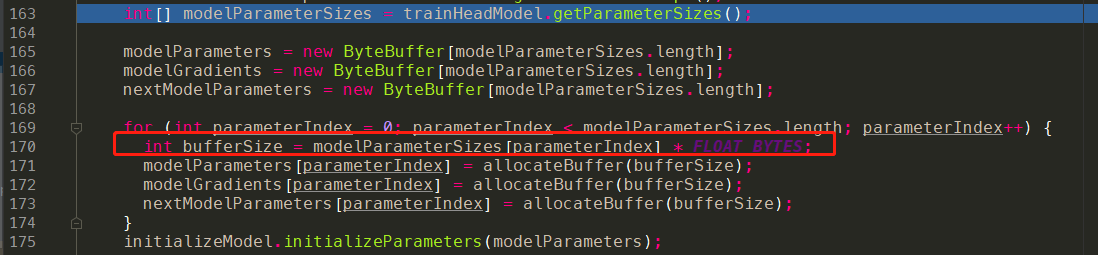
最终,modelParameters,modelGradients,nextModelParameters这三个变量的值如下:
通过观察,其实我们可以知道
index 0 对应的是:head/placeholder_ws
index 1 对应的是:head/placeholder_bs
optimizerState,nextOptimizerState
这两个参数是属于optimizerMode的,所以对应的就是optimizer.tflite
调用代码:onCall
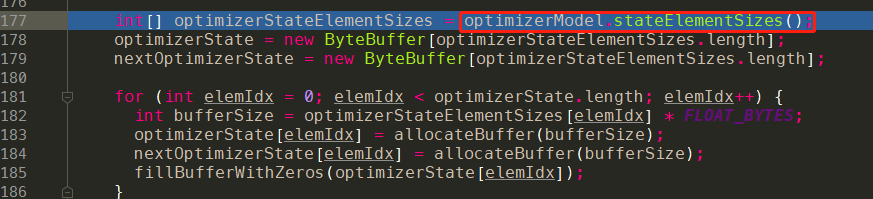
实现代码:onImpl
tflite模型图示:
代码解析:
这个函数stateElementSizes实际需要结合tflite的结构图来看。
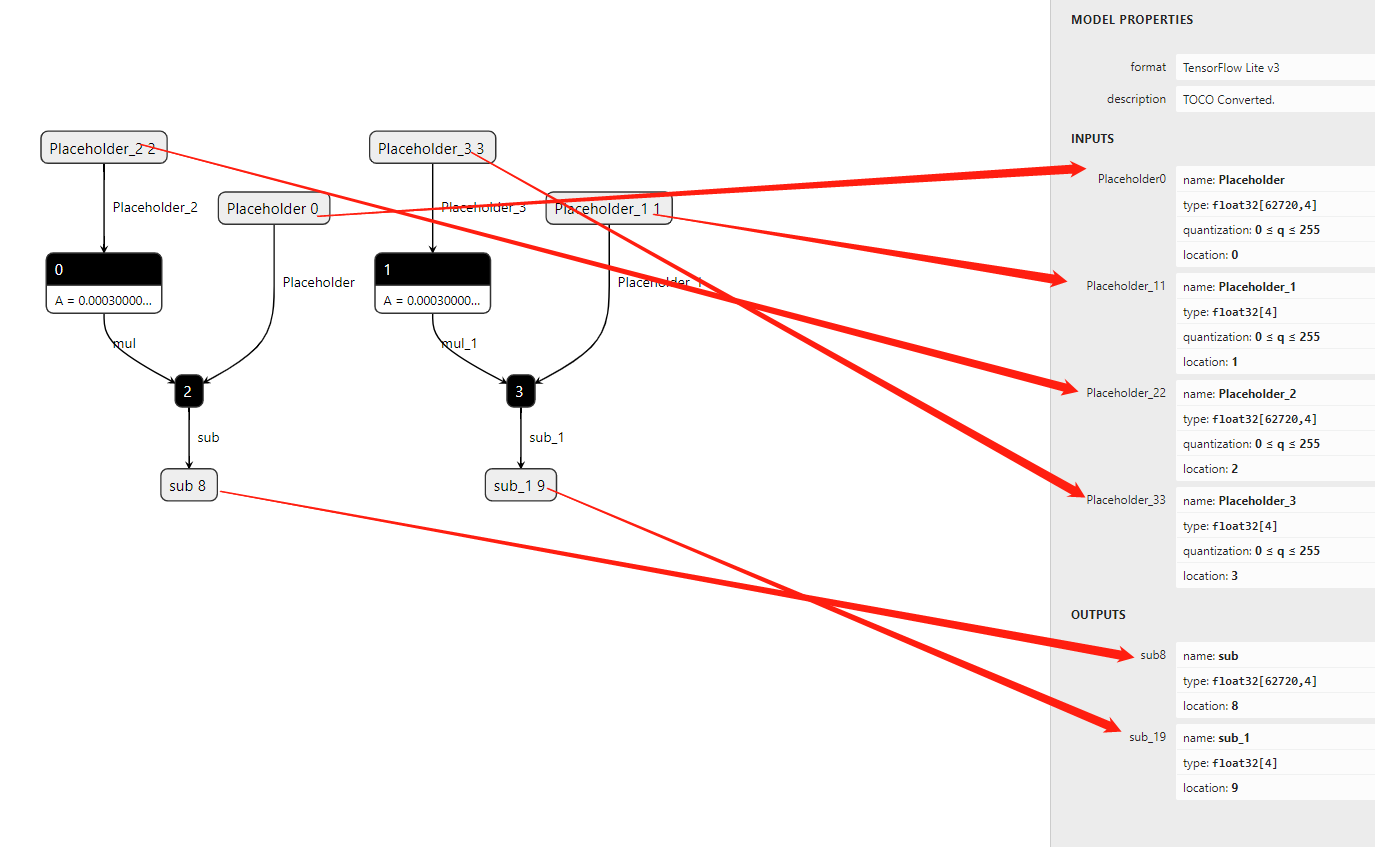
从optimizer.tflite的图中,我们可以看到有4个input和两个output。- input:
- Placeholder:[62720,4]
- Placeholder_1:[4]
- Placeholder_2:[62720,4]
- Placeholder_3:[4]
- output:
- sub:[62720,4]
- sub_1:[4]
从tflite的计算图中,我们可以看到
12sub = Placeholder - Placeholder_2 x 0.0003sub_1 = Placeholder_1 - Placeholder_3 x 0.0003这里是一个比较典型的迭代计算,其中
0.0003可以认为是学习率。有了以上的知识储备,我们再看来
stateElementSizes的具体实现就会好理解一些了。字面含义,这个函数是为了计算出numVariables的数量,由于optimizer.tflite的特性,我们这边只用到了4个input和2个output,由上面的计算也可知,一个output其实是通过两个input更新得来的,因此回过来继续看代码:12345int numVariables =modelWrapper.getInterpreter().getInputTensorCount()- modelWrapper.getInterpreter().getOutputTensorCount();int[] result = new int[modelWrapper.getInterpreter().getInputTensorCount() - numVariables * 2];实际:
numVariables = 2,int[] result = new [0],回到代码中:
这一大段其实都是0。- input:
最终,optimizerState,nextOptimizerState:
题外话,这段代码究竟有没有含义,其实是有含义的,就是在optimizer.tflite中如果还有其他参数需要更新的情况下就会有用了,比如做其他运算,或者是学习率随着step变多而下降之类的。
trainingBatchBottlenecks
这个参数可以认为是训练时传给trainedHead的input。因此整个大小其实可以认为是batchSize x bottlenectSize
调用代码:onCall

实现代码:onImpl
public int getTrainBatchSize()
int getBatchSize()
private int numBottleneckFeatures()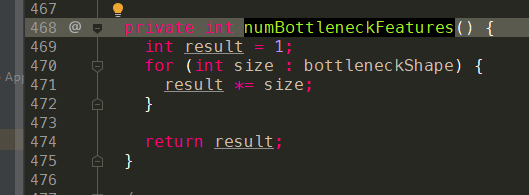
tflite模型图示:
- trainHead.tflite
- trainHead.tflite
代码解析:
在整个迁移学习的过程中,我们是把bottleneck.tflite的输出直接接到trainHead.tflite的输入上,开始做训练的,因此很自然的就可以得出:1trainingBatchBottlenecks = ByteBuffer.allocateDirect(20 x (7 x 7 x 1280) x 4)
trainingBatchClasses,zeroBatchClasses
从命名上来看,这两个变量其实都是为了最终output服务的,在分类算法中,我们一般会把output的结果做成onehot向量,也就是标志分类的那个序号的值为1,其他的为0。
- 调用代码:onCall

getTrainBatchSize的部分在上述已经介绍过,batchSize = 20,其中class分类目前限定为4,因此:int batchClassesNumElements = getTraiatchSize() * classes.size() = 20 x 4 = 80
最终,trainingBatchClasses,zeroBatchClasses:
inferenceBottleneck
通过分析trainingBatchBottlenecks的阶段,其实我们不难得到inferenceBottleneck。inferenceBottleneck = allocateBuffer( (1x7x7x1280) x 4);
- 调用代码:onCall

模型参数的训练
模型的训练分为两步:
- 数据采集,分为源数据采集和标记
- 迭代训练,epoch,batch
数据采集:addSample
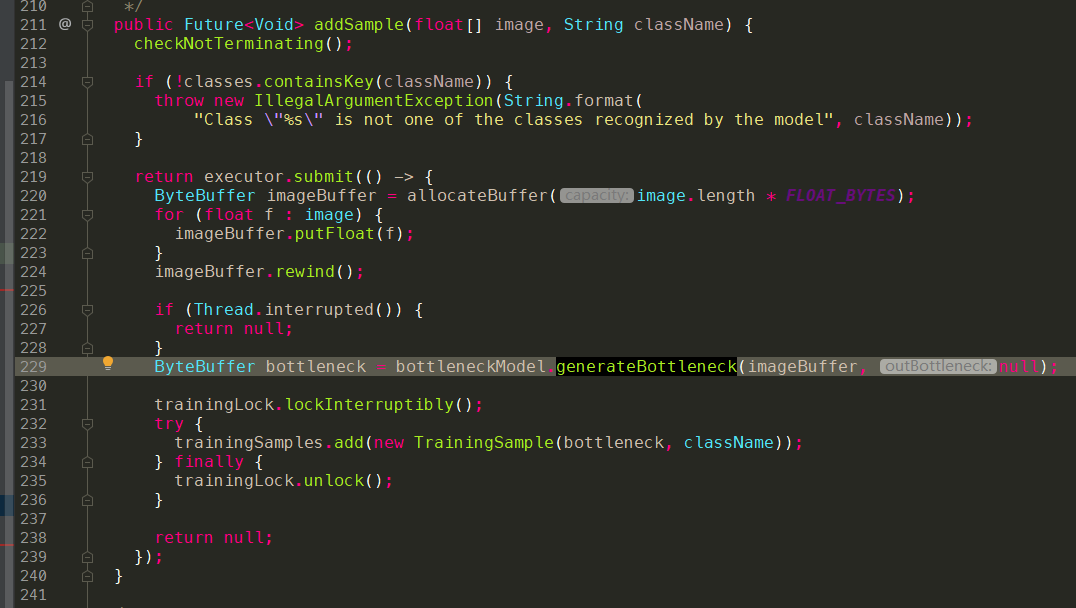
addSample的动作其实是把图片先传入bottleneck.tflite做一次计算,获取到对应的bottlenect值,然后把bottlenect和class标记一起存下来。
代码整体流程:
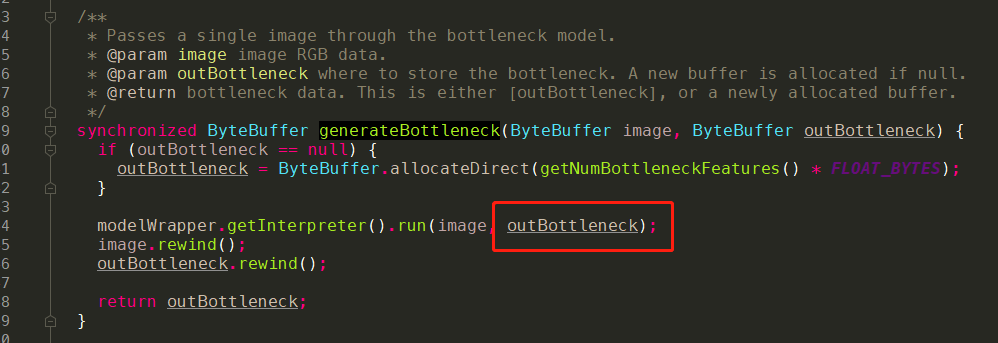
bottlenect.tflite实现:
训练:train & 参数更新
整个模型的训练过程其实跟Server端的训练并没有太大的差异,整体思路上面:
流程简介
- 随机挑选一批数据作为input,记为X
- 把X带入模型,进行正向推演,获得推演的结果Y
- 使用Y和真实的标记结果Yt,通过合适的Loss函数,计算Y与Yt的偏差
- 使用反向传播算法,通过Y与Yt的偏差逐层反向更新参数W0,W1,…,Wx
- 回到第一步,进行下一轮正向推演
术语上,我们称epoch为代,batch为批,训练的时候数据是一批(batch)一批送入的,理论上每一批的数据都是不同的,当把所有的训练数据都训练到时,我们称训练了一代(epoch)。
一般来说,训练是以代(epoch)为度量单位的,一般都说我们把数据跑多少代(epoch),而不是多少批(batch)。
我们跑3个epoch吧,然后看看结果!!!
代码实现
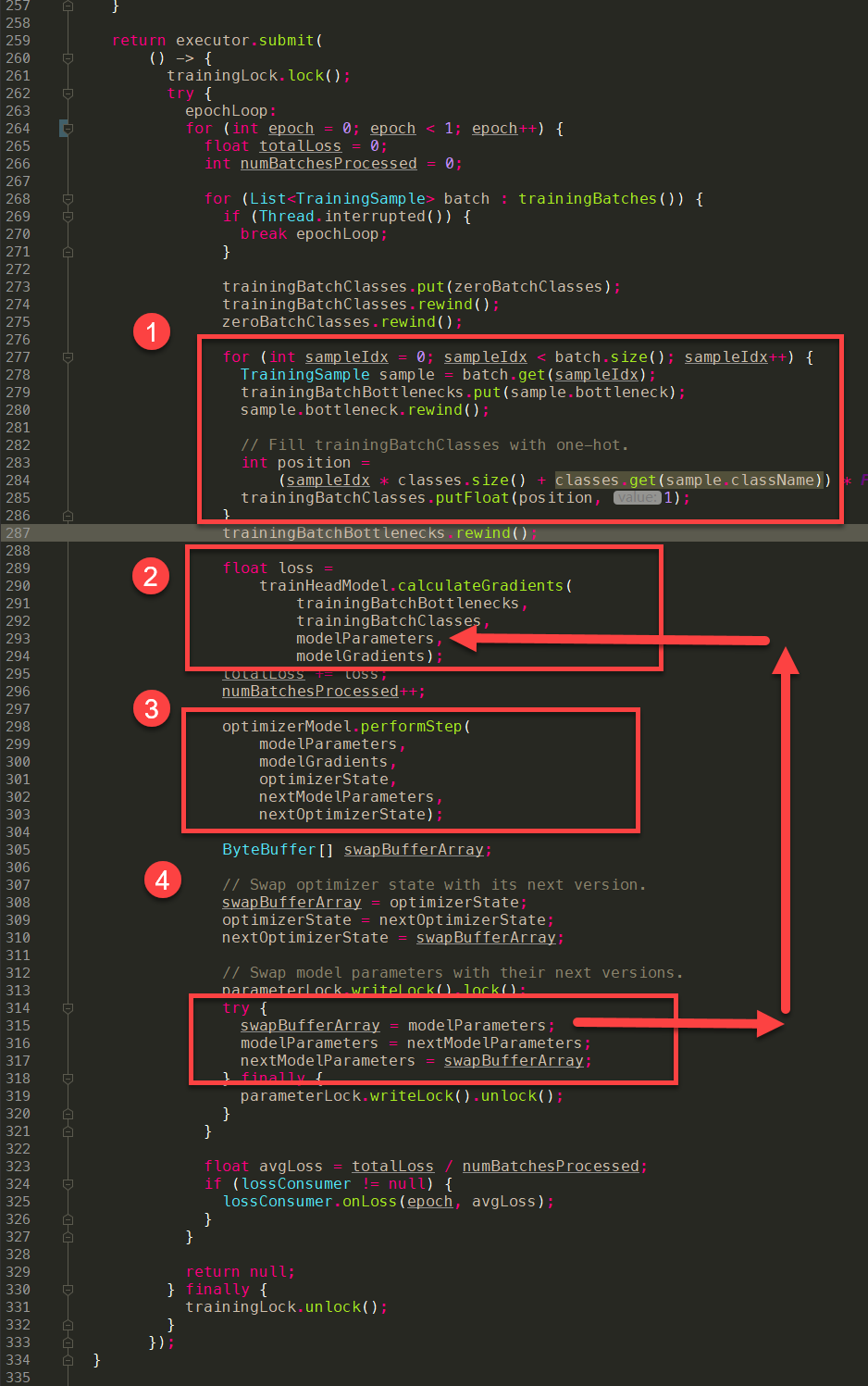
- 随机挑选一批数据作为input,记为X
- 整体做法比较粗暴,会从
List<TrainingSample> batch拿出数据 - 直接填充到
trainingBatchBottlenecks,这个变量我们之前有讲过,刚好是可以放下20个bottleneck:trainingBatchBottlenecks = ByteBuffer.allocateDirect(20 x (7 x 7 x 1280) x 4)- 同样的,这边还会记录Yt:
trainingBatchClasses,由于这个是onehot向量,因此会在对应class的index的位置写1,其他地方写0。
- 同样的,这边还会记录Yt:
- 整体做法比较粗暴,会从
- 把X带入模型,进行正向推演,获得推演的结果Y
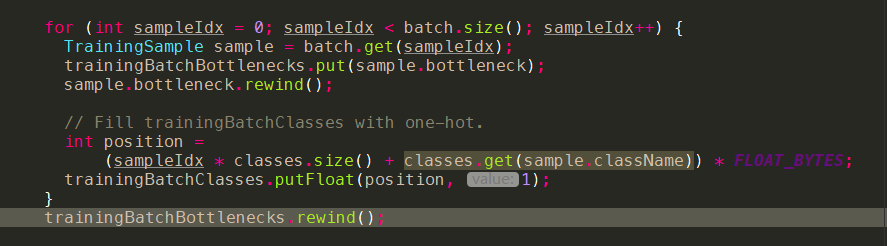
使用Y和真实的标记结果Yt,通过合适的Loss函数,计算Y与Yt的偏差
- 代码调用:onCall
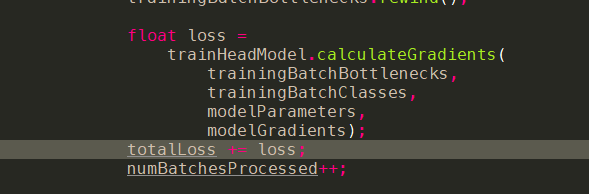
- 代码实现:onImpl
- trainHead.tflite
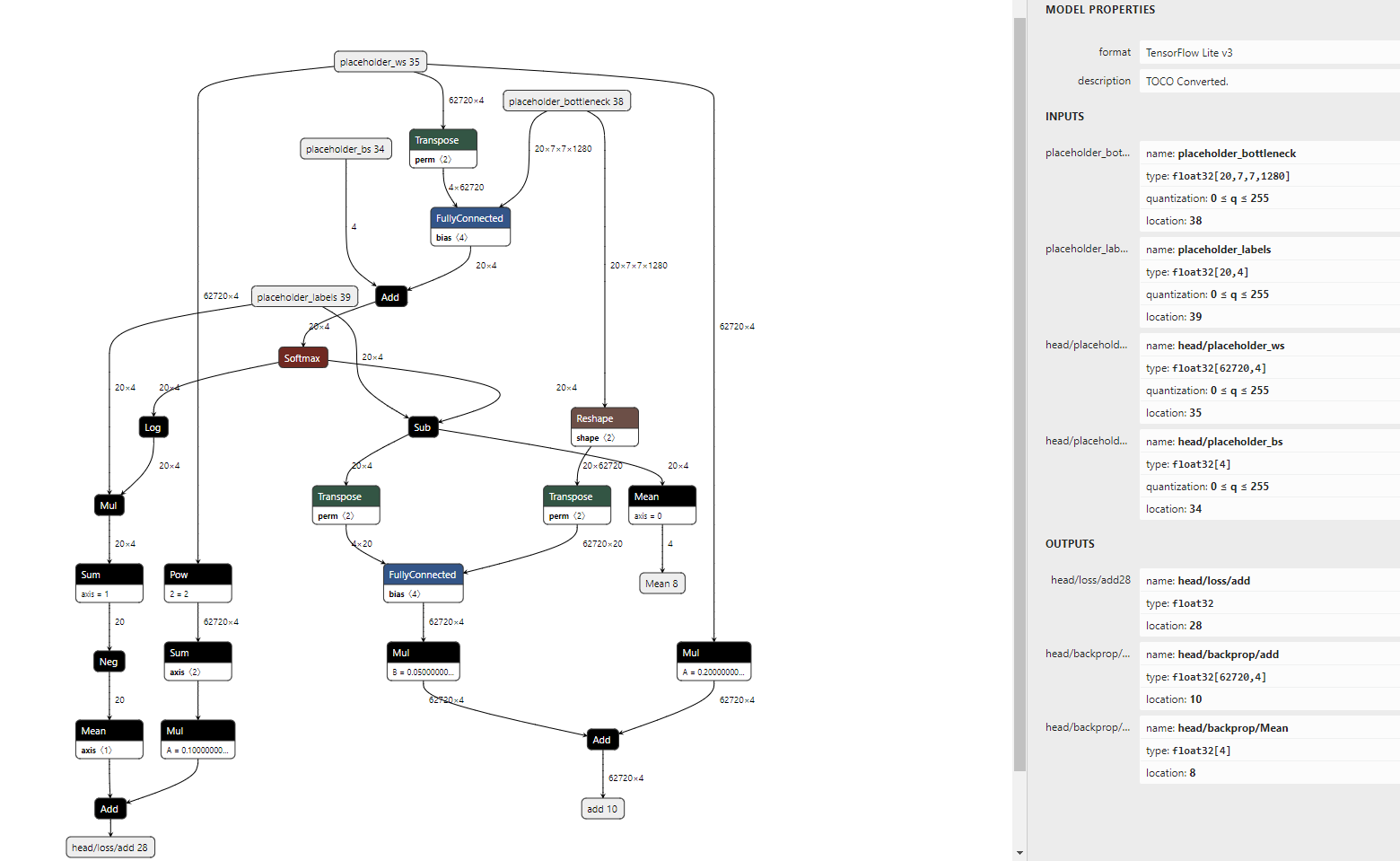
- 代码讲解:
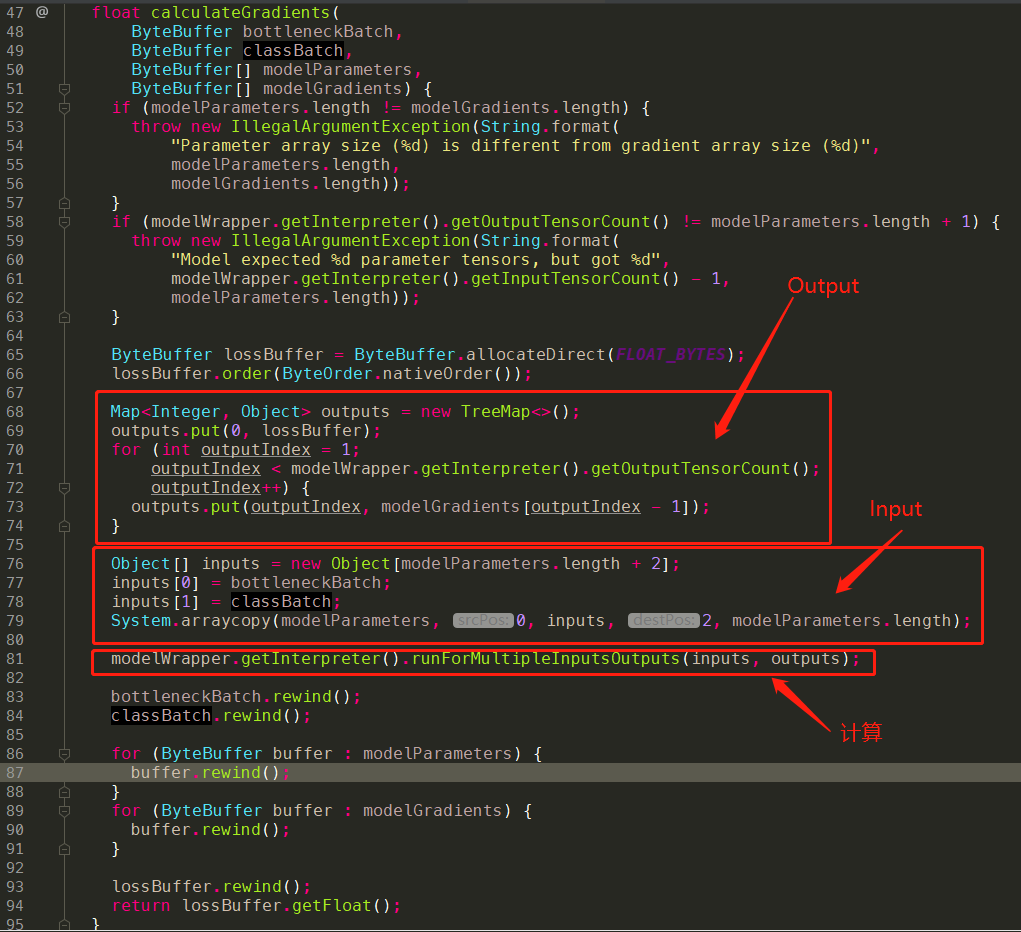
- 根据
trainHead.tflite,我们可以看到实际input的部分有4个- placeholder_bottleneck:trainingBatchBottlenecks
- placeholder_labels:trainingBatchClasses
- head/placeholder_ws:modelParameters[0]
- head/placeholder_bs:modelParameters[1]
- output的部分有3个
- head/loss/add:head/loss/add
- head/backprop/add:modelGradients[0]
- head/backprop/Mean:modelGradients[1]
因此,整个trainHead.tflite不仅完成了正向推演的过程,顺便还做了反向传播中的梯度计算,并得到了梯度的值,这一部分可以顺着placeholder_labels节点去看会比较明确。(具体的推导过程需要结合反向传播的知识,以及对应求导公式来看,这个需要重新学习以后才可以讲的明白)
- 根据
- 使用反向传播算法,通过Y与Yt的偏差逐层反向更新参数W0,W1,…,Wx
- 代码调用:onCall
- 代码实现:onImpl
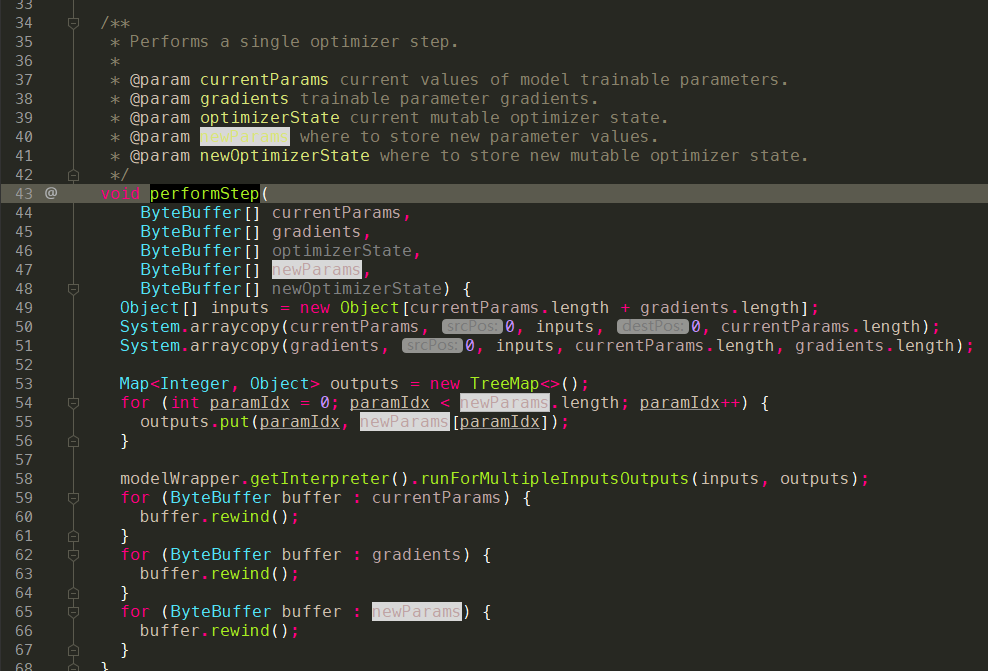
- optimizer.tflite
- 代码讲解:
这部分其实在optimizerState,nextOptimizerState这个章节已经说过了,对于optimizer.tflite来说,其实就是利用了学习率和梯度值去更新参数,学习率是0.003,参数的梯度值是上一个步骤中通过trainHead.tflite训练获得的。
获取到更新后的参数,通过swap赋值,然后进行下一轮迭代。
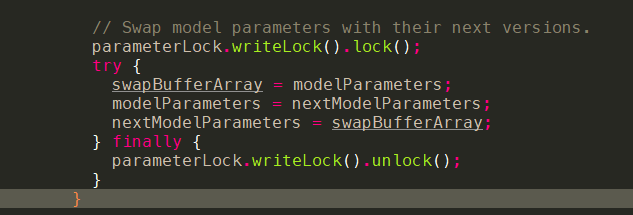
- 代码调用:onCall
- 代码调用:onCall
最后再回顾一下这四个步骤:准备批数据,正向推演,反向传播更新参数,迭代批数据。
模型应用以及识别
我们重新关注一下inference.tflite的模型结构: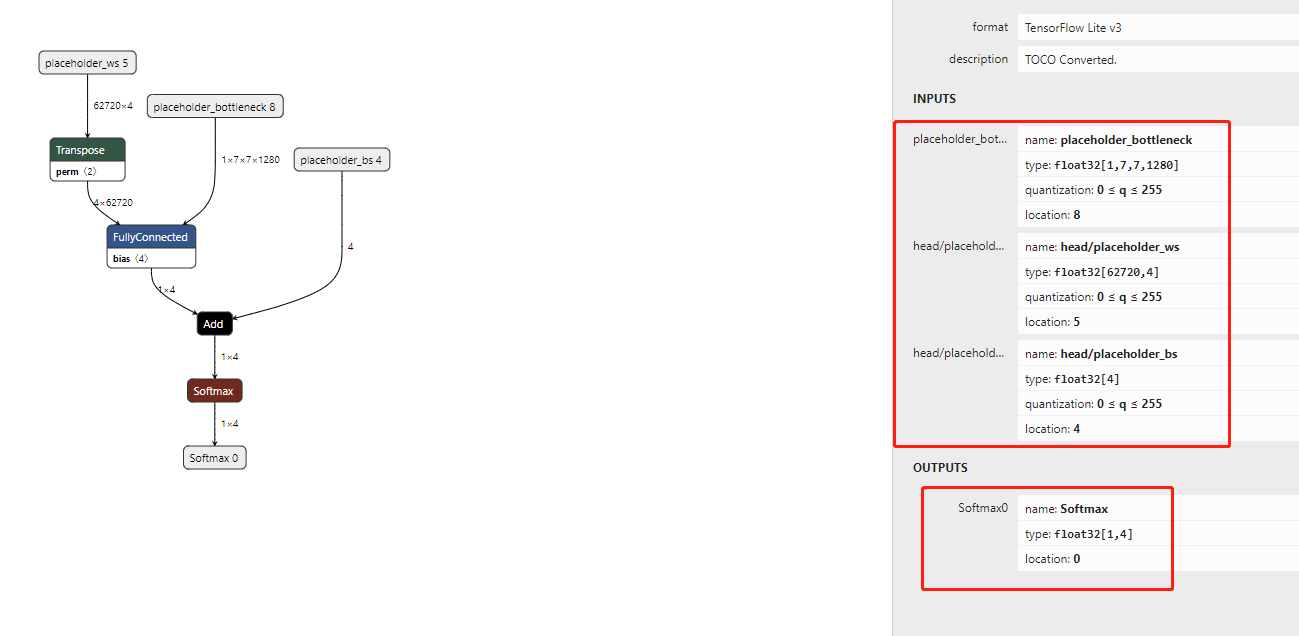
通过上述模型参数的训练章节,我们已经了解了:
- head/placeholder_ws:modelParameters\[0\]
- head/placeholder_bs:modelParameters\[1\]
这两个参数在实际代码中,会不断迭代更新,从而使得Loss降低,模型的识别变好,而bottleneck的值,是通过bottleneck.tflite模型的计算得到的,因此在inference.tflite模型中,我们只需要把之前训练好的modelParameters以及通过bottlenect.tflite计算得到的bottleneck作为input传入,就可以得到预测值了。实际代码也就是这么做的,这里就不做赘述了。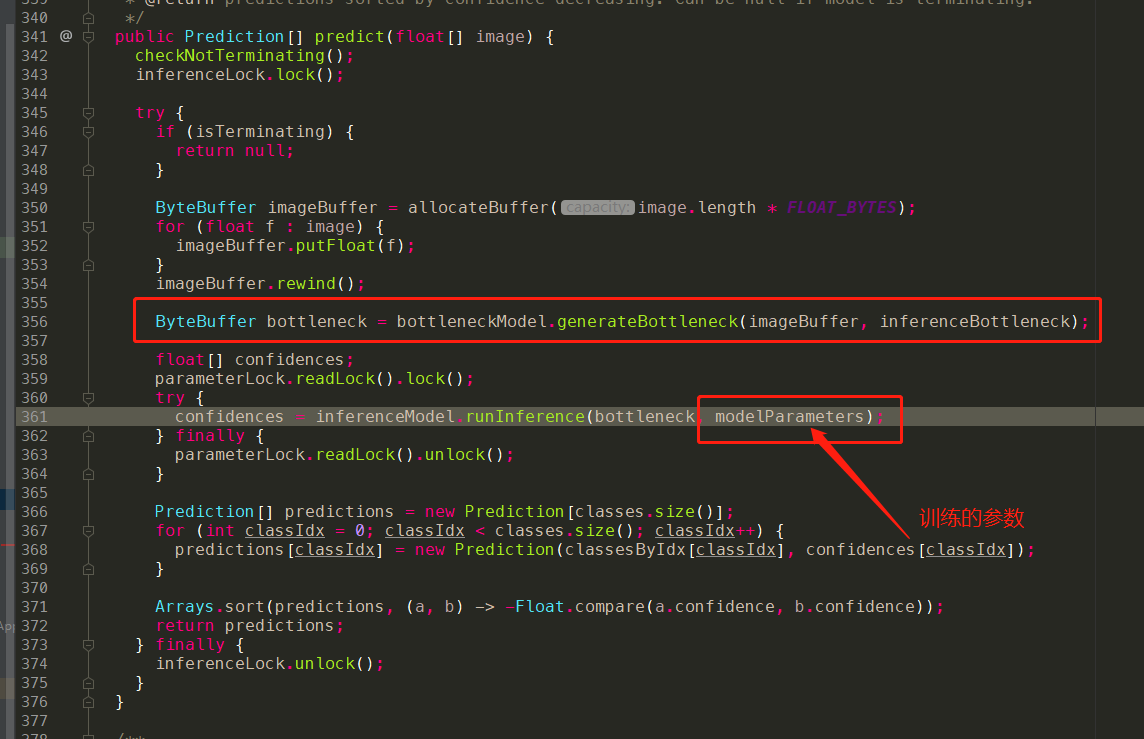
写在最后
《model_personalization》在手机端实现了一个轻量化的迁移学习训练网络,通过层层分析,其实整体思路跟在Server端训练是一样的,甚至说我们可以直接手写一个训练网络,也是可以实现简单的离线训练(但是懒)。
利用tflite的现成工具,可以说是极大的提高了整个训练和建模的效率,从目前的效果上看,迁移学习的最终效果还不错,但由于该项目把所有的资源都加载在内存里,会导致整体app的内存占用量过大,这个在实际产品化的过程中需要做一定的优化。
整个工程代码结构简洁明了,线程安全到位,思路也很顺,确实是google出品的好东西。