工作中的常用命令分享
大部分的命令都是常规性的,比如过滤日志的grep,抓日志用的adb logcat,这边主要就这两个场景做一下扩展。
1.从一份离线日志包中按时间顺序找出指定某个进程的所有日志
- 我们通常拿到的离线日志包,会带有非常多的文件,因为日志的部分是一直在抓并实时保存的,如下图:
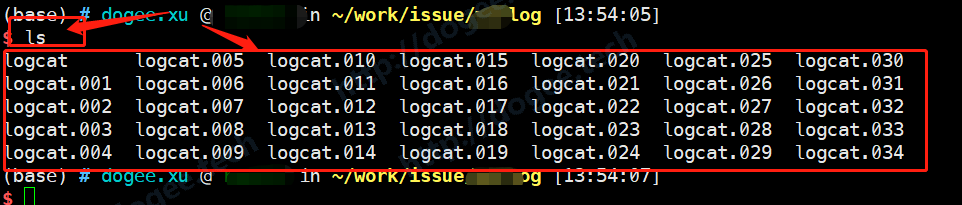
- 这些日志被整齐的划分成4MB左右的大小,按照后缀名的顺序,对应的时间是由近到远,也即
logcat为最近时间,而logcat.034是最远的时间。
- 所以我们的诉求也就很简单了,就是按照文件名的倒序顺序,把
logcat.034,logcat.033,…,一直到logcat.001,logcat这些文件中指定进程id的日志捞出来。、- 需要注意的是,我们这边的日志有一个大前提:按照时间顺序,因此直接在当前目录下用
grep命令的话无法保证所有的输出是严格按照时间顺序的。
- 需要注意的是,我们这边的日志有一个大前提:按照时间顺序,因此直接在当前目录下用
因此我们整个动作的分解行为:
拿到倒序的文件名列表:ls -r,参数
r,代表了reverse,可以比较一下带r和不带r的区别。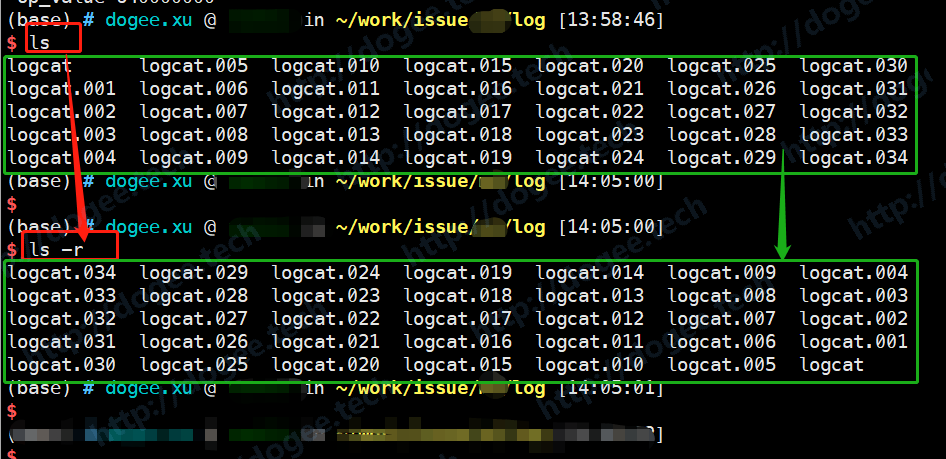
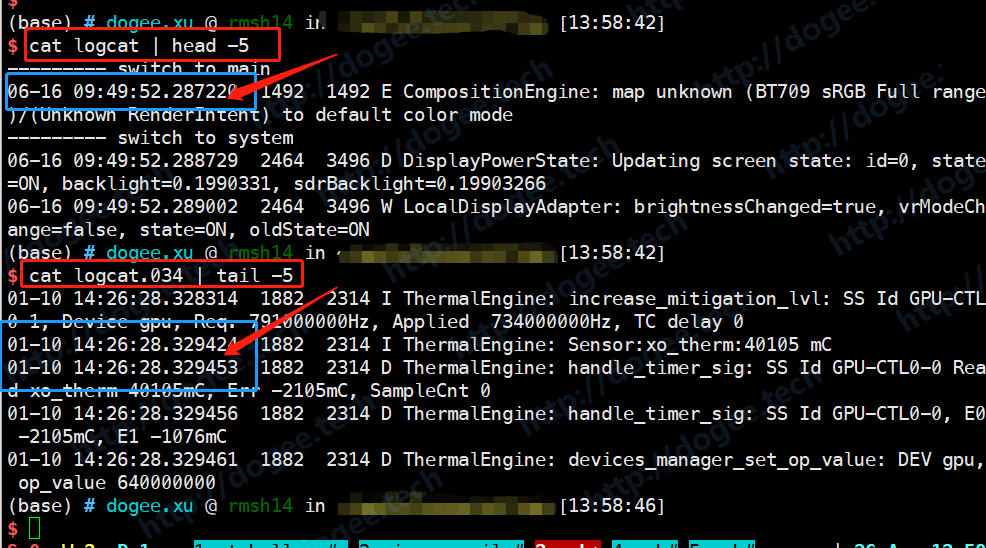
使用
grep命令,挨个过滤日志文件中的指定进程id,获取特定进程的日志,比如我想过滤进程id为1882的信息。- grep “1882” logcat.034,grep “1882” logcat.033,依次类推,grep “1882” logcat.001,grep “1882” logcat
- 当然,grep命令也是有一些参数的,我一般常用的参数有:r,n,s,H,E,i
- r:recursive,递归查询,会搜寻指定目录下的所有文件和目录
- n:line-number ,在搜索结果中显示出结果所在的行号
- s:no-message,不显示命令运行时的错误信息
- H:with-filename,在搜索结果中显示出结果所在的文件名
- i:ignore-case,搜索时忽略字母的大小写差异
有了以上的知识储备,我们通过管道命令
|以及参数xargs命令,把以上两个步骤串起来:- ls -r | xargs -I {} grep -nsH “ 1882 “ {}
其中xargs命令,实际可以认为是把管道
|的每一个输出作为它的输入,挨个执行后面的命令I,字母i的大写,默认是把每个参数使用某个替换符替换,默认是{},所以xargs -I {}的意思就是把前面管道的output的参数,使用{}代替,来跑后面的命令,即:xargs -I {} grep -nsH " 1882 " {}等价于grep “1882” logcat.034,grep “1882” logcat.033,…,grep “1882” logcat.001,grep “1882” logcat
- ls -r | xargs -I {} grep -nsH “ 1882 “ {}
最后,我们需要把输出的文件保存到一个新的文件里面,这样方面日后的查阅,另外为了不造成递归死锁,因此我们保存的文件记得跟查询的目录不是同一个目录。
ls -r | xargs -I {} grep -nsH “ 1882 “ {} > ../save_1882.txt
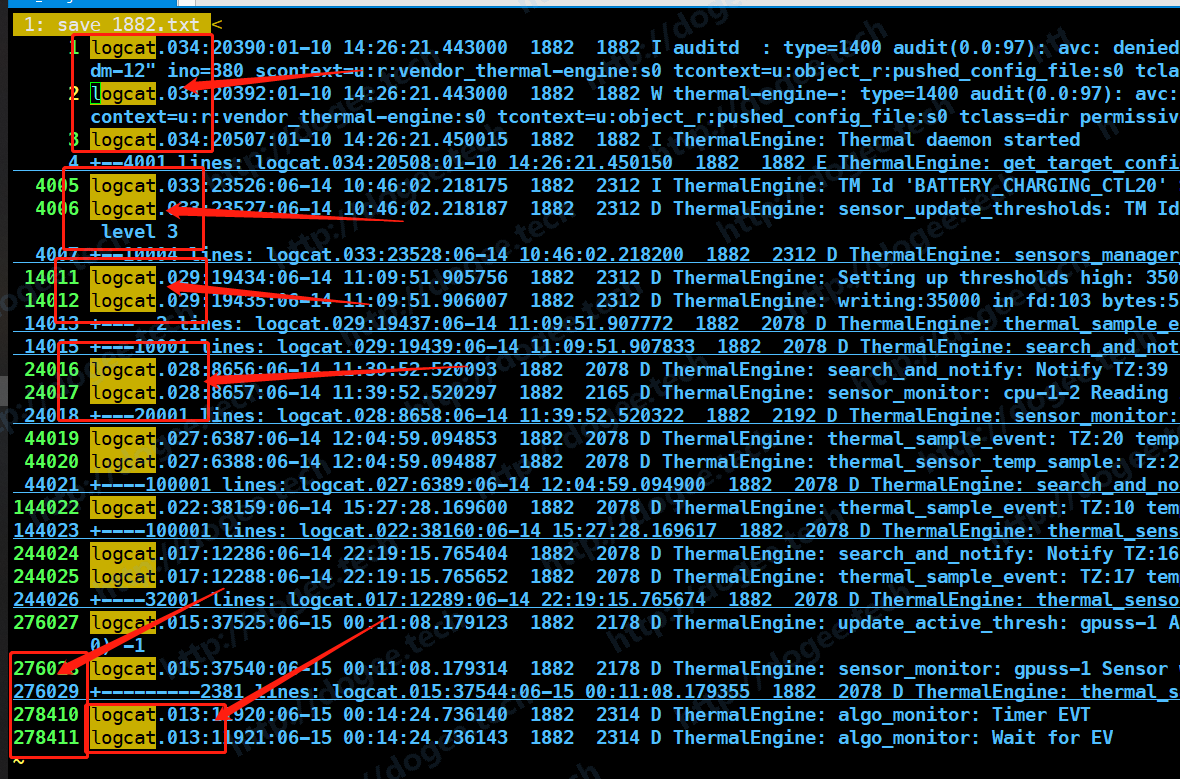
- 最终输出的文件有278411行,时间是按照正常的顺序时间往下的,其中日志的输出带上了文件名和行号。
- 为什么要带上文件名和行号?
- 因为我之前经常是分析系统问题的,因此当发现某个进程在某个时刻出现异常时,需要回到当时的时间点去查看整个日志的上下文,这个时候使用grep命令n,H参数获取到的行号,文件名就很有帮助,可以快速帮我找到那个时间点的具体位置
- 为什么要带上文件名和行号?
技巧点:管道命令”|”,过滤命令grep,参数命令xargs
2.logcat的一些参数
一般做应用开发的同学,在抓取日志的时候都会依赖IDE工具,而这类IDE工具比如Android Studio会针对logcat的原始输出做一下格式化,也就是俗称的format。由于常年在工作中扮演着擦屁股的角色,导致我在抓日志上不太相信自己以外的人,尤其是集成度特别高,做了特别多工作的IDE工具,总觉得它会“丢”日志,而实际也是这样,在IDE密密麻麻的按钮上随意点上几个,勾选几个,就会导致日志的不全。
下面是Android Studio中我随手抓的一个图,其中黄色框的部分就是有坑的点了,随便选一下,填一下就会导致“丢”日志。
直接抓logcat的话,相对来说看到的就是这样的:
两张图乍一看似乎没什么区别,但是logcat 还有着更多的命令组合:
-b:输出指定的buffer日志,
adb logcat -b buffer名字,一般我们的buffer有:- radio:一般跟phone业务相关的日志,会输出在radio buffer
- events:这个在system ui和system server中比较多,一般长这样。
- main:主要的日志buffer,但是这个buffer不包含
system和crash,所以有些人直接输入main会发现没有SystemServer或者是Crash的相关信息 - system:一般认为是Android SystemServer或者是System UID进程的日志
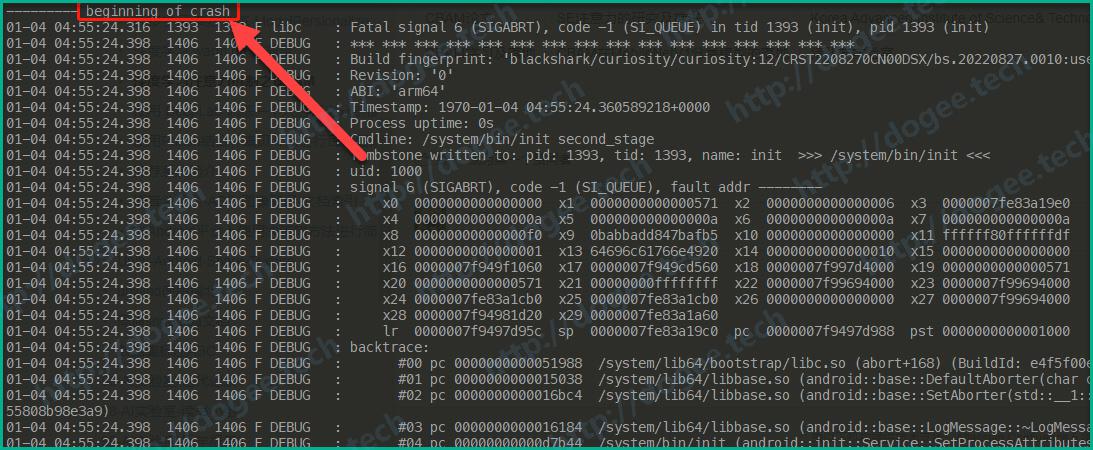
- crash:发生崩溃的日志区,一般来说只要发生了crash,不管是Android Java端Runtime的还是Native的Tombstone,直接查看这个buffer都是可以的。对于快速定位crash的日志特别有帮助。
- kernel:kernel的buffer日志,一般就对应着”dmesg”的日志输出
- all:输出所有的buffer日志,我一般都会使用这个标志,以免丢失了信息
- default:包含
main,system以及crash三个,如果直接输入adb logcat那么就会输出这三个
-D:注意这里不是小写
d,而是大写D,其作用是在各个不同的buffer的打印中增加一个分割线- -c:clear参数,清空-b参数对应的buffer,如果没有带-b参数,那么默认就是
main,system,crash三个buffer - –pid:具体的进程名,可以仅输出对应进程号的日志。
adb logcat --pid=5534
综上,我一般在使用中会先使用adb logcat -b all -c清楚当前logcat中所有buffer的日志,然后再紧接着使用adb logcat -b all -D来获取所有buffer的日志,继而再进行常规的复现操作来抓取现象日志,这样在整个操作中,我可以保证获取到main,crash,kernel,system这几个关键buffer的日志,同时因为-D的加入,会有分隔符出现,在整个整机行为的时候会更加有效。
这个部分最好的教材还是Android Developer:https://developer.android.com/studio/command-line/logcat
技巧点:logcat参数,-b 指定buffer,–pid指定进程
3.UltraEdit“列模式”使用技巧
UltraEdit是一个功能非常强大的编辑工具,我经常使用其中的正则表达式和竖行编辑功能,也就是列模式。
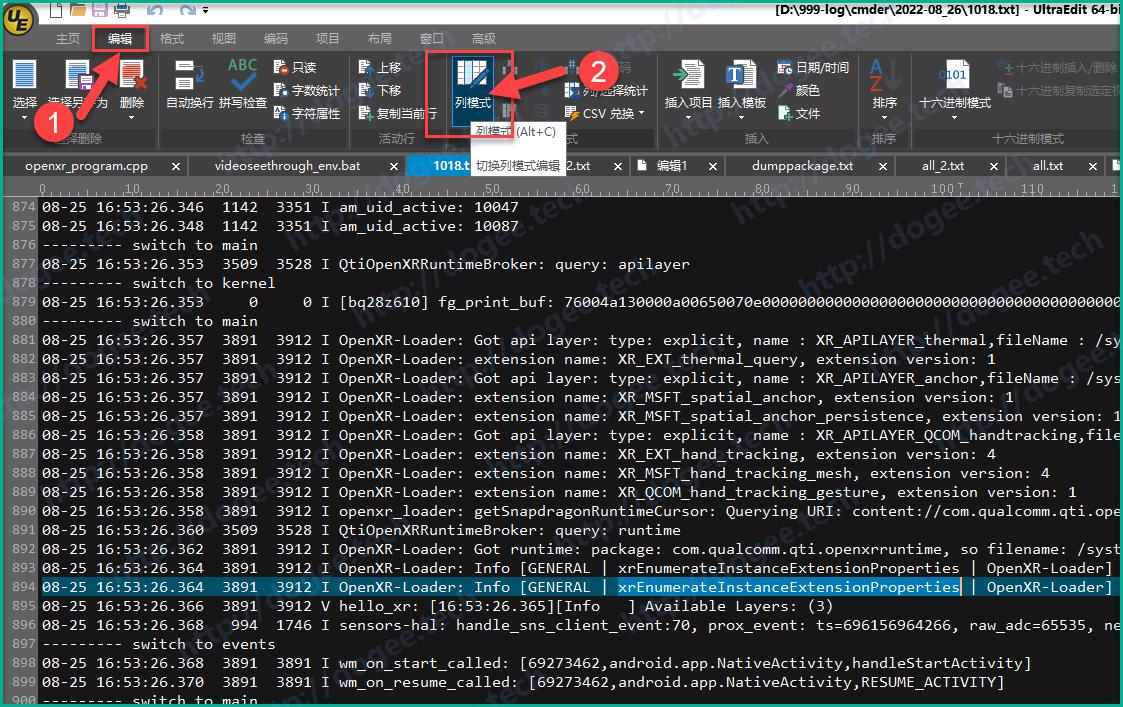
选中编辑菜单
找到列模式,点击启用列模式
在这个模式下,会改变原来按行选取的方式,可以直接按列进行编辑
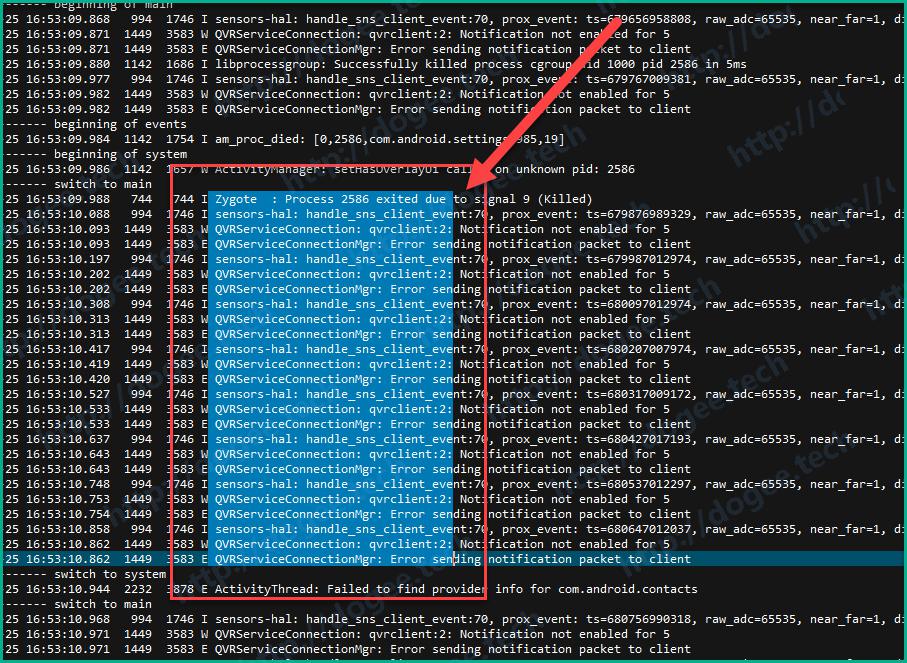
- 这个时候就可以按照列模式来选取编辑区域了,比如这个时候就可以按列删除,只删除框选区域内的内容。
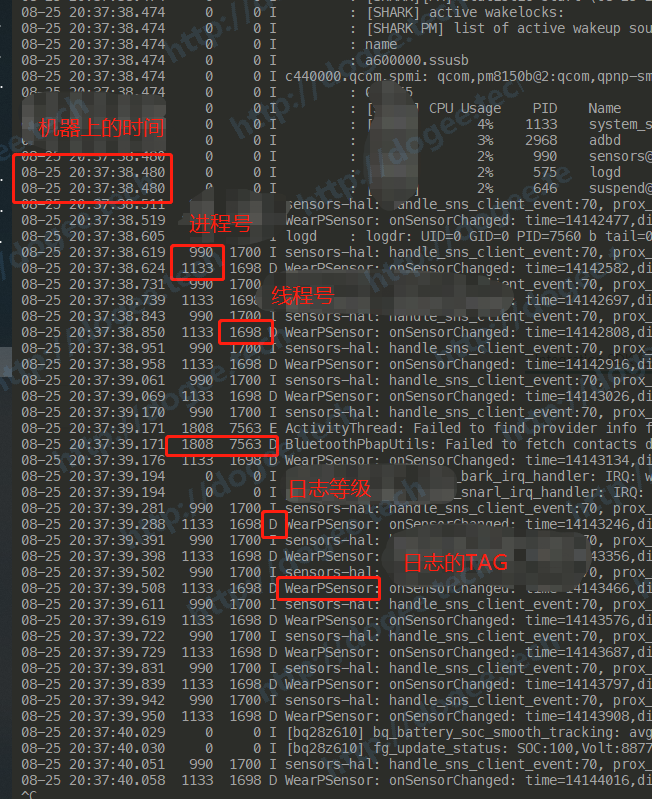
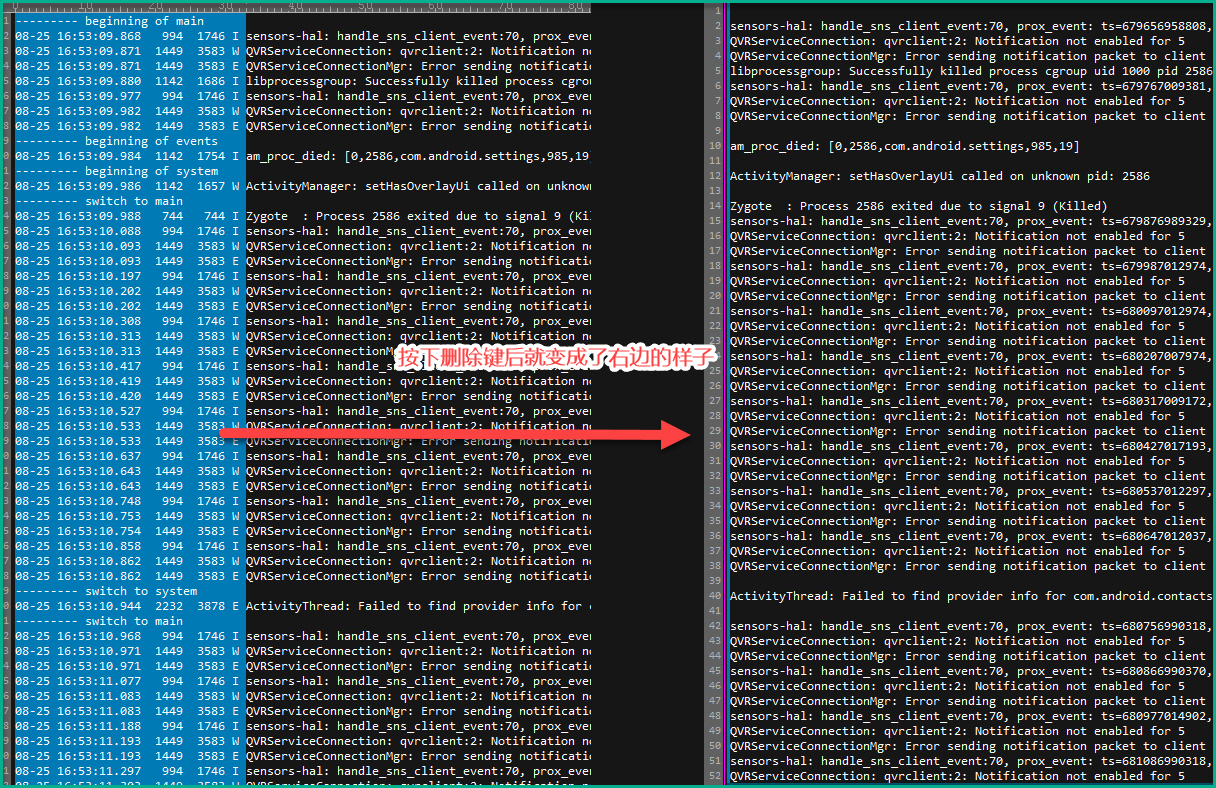
更多的时候,我们可能想把最前面的时间,进程,线程号的信息去掉,只想保留TAG的部分,那么就可以:
或者还有一种用法,就是在前面一律增加某个字段
正则表达式的部分,我放在最后说,这个部分其他的编辑器也会有,所以是一个共性的知识点。
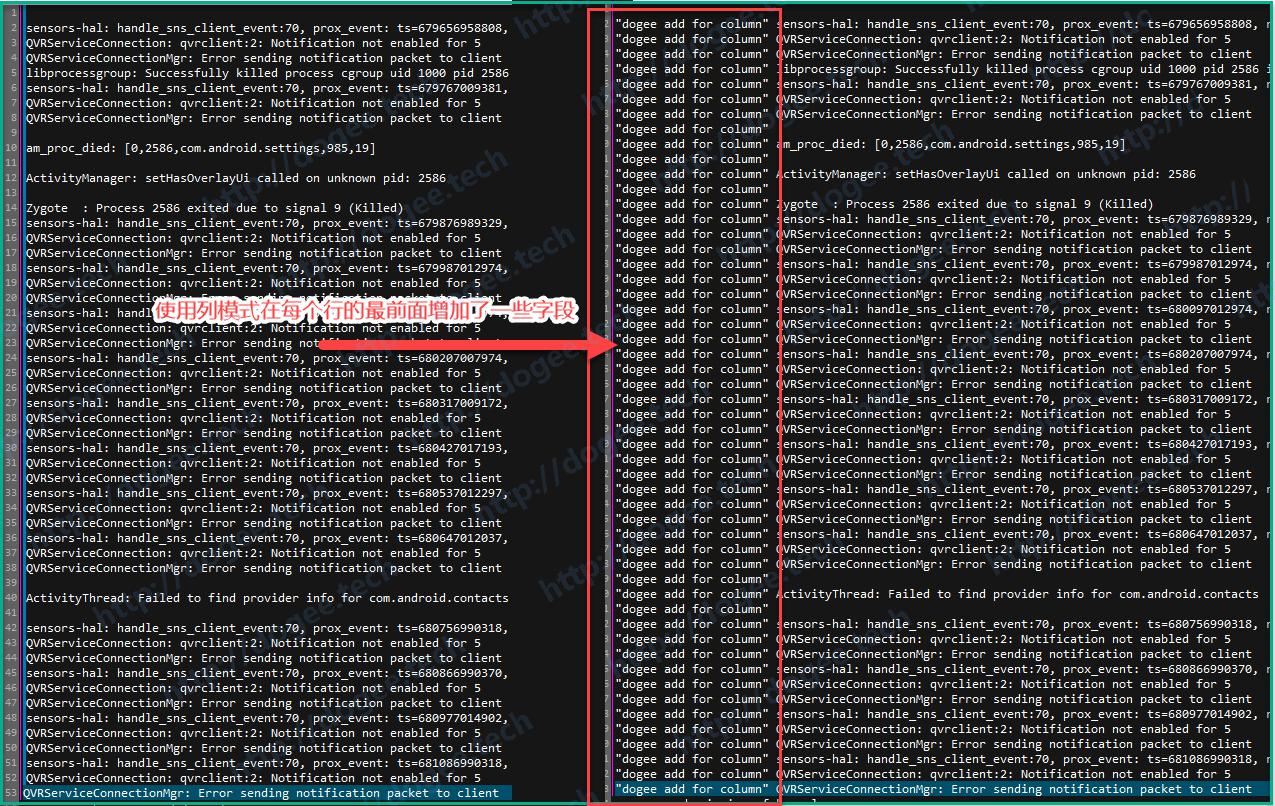
技巧点:列模式
4.awk命令使用技巧
在文本处理的过程中,有些时候需要提取一些关键信息,比如在这个文件中,我们需要提取出不同模块下的position数据。
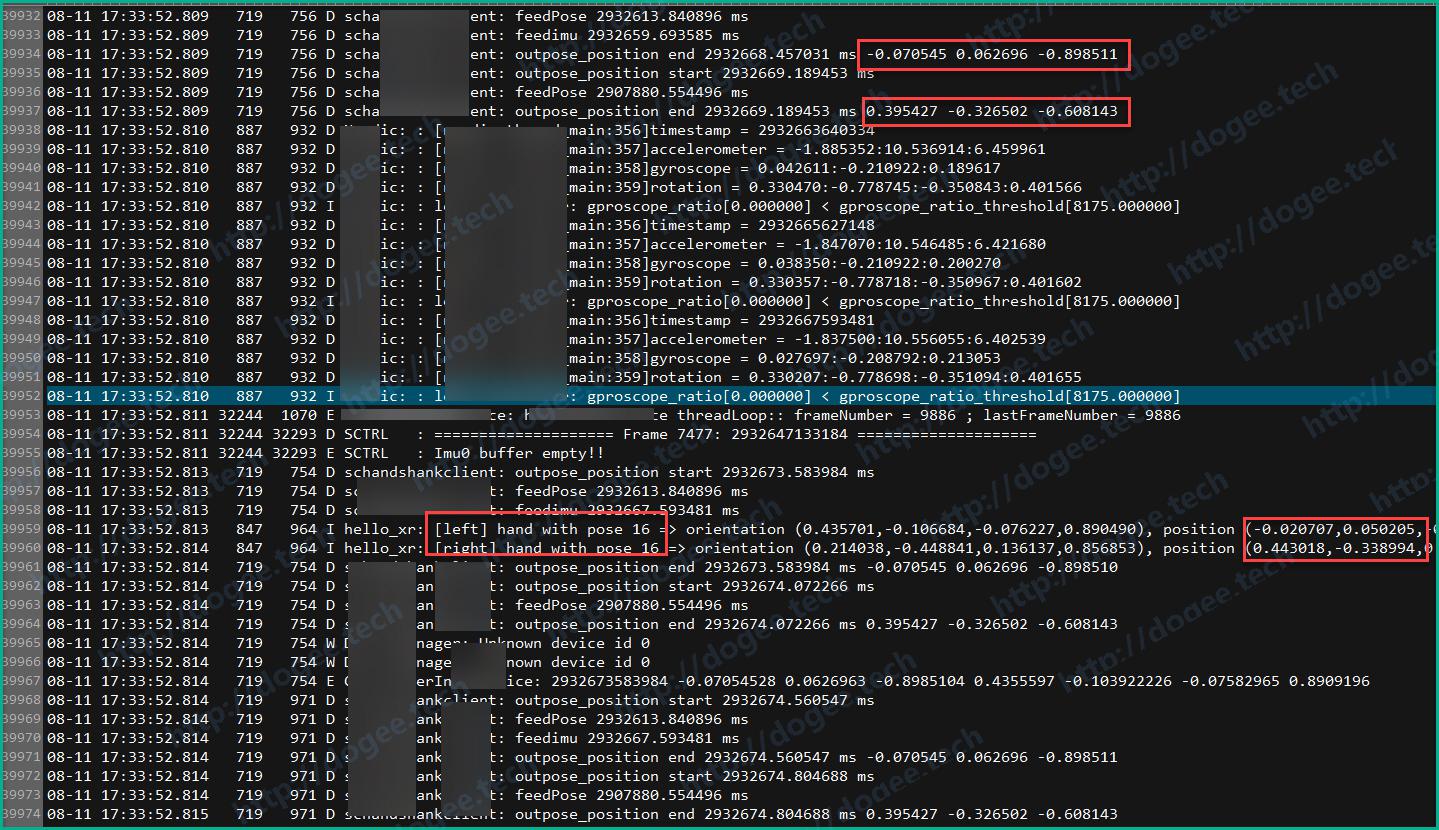
日志的pattern大概是这样的:
08-11 17:33:52.809 719 756 D XXXXX: outpose_position end 2932669.189453 ms0.395427 -0.326502 -0.60814308-11 17:33:52.813 847 964 I hello_xr: [left] hand with pose 16 => orientation (0.435701,-0.106684,-0.076227,0.890490),position (-0.020707,0.050205,-0.075741)08-11 17:33:52.814 847 964 I hello_xr: [right] hand with pose 16 => orientation (0.214038,-0.448841,0.136137,0.856853),position (0.443018,-0.338994,0.392468)
我们需要做的是分别提取
XXXX日志中的position字段,但是在实际操作中,因为每个pattern的字段都不太一样,所以没有办法做到一次性获取,我的做法比较搓先依次
grep关键字:XXXXX: outpose_position end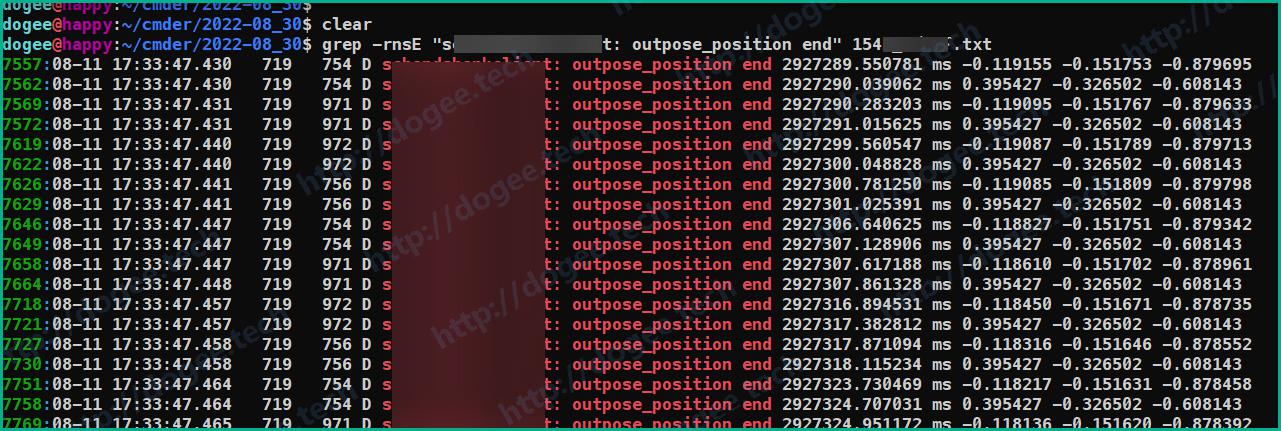
I hello_xr: [left]I hello_xr: [right]
再使用
awk+print命令,从上述结果中获取对应的position数据整个命令序列为:
grep -rnsE "XXXXXX: outpose_position end" 1543_2上下.txt | awk '{printf "%s %s %s\n",$11, $12 ,$13}'- 其中
awk如果是跟print命令,那么就是简单的输出 - 如果是跟
printf命令,那么就是跟格式化的输出,和C语言的用法一致
- 其中
awk的基本用法可以参考:https://www.runoob.com/linux/linux-comm-awk.html其中
print的默认分隔符为空格,也可以使用-F参数来指定其他的分隔符,还是比较灵活的。
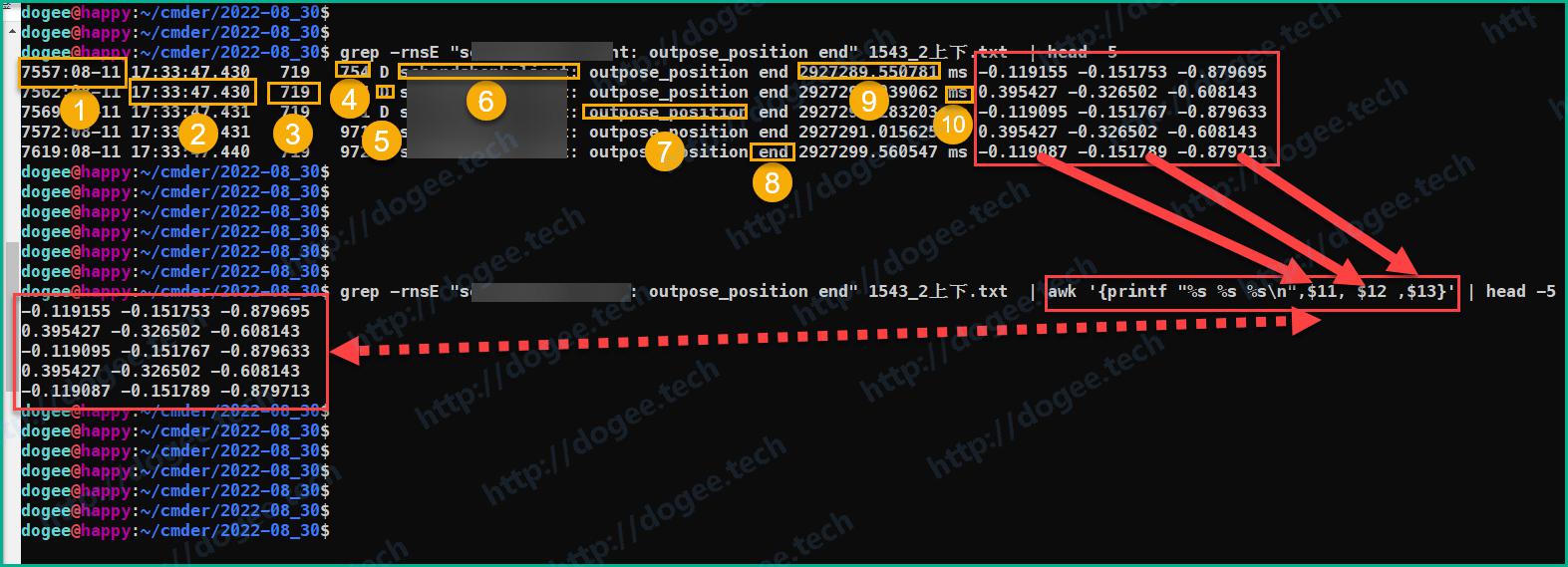
以上是使用awk+print/printf来对文本做处理的一个范例,下面再举另外一个例子:抓取特定进程名的日志。
先使用
adb shell ps | grep system_server,获取到了system_server进程的信息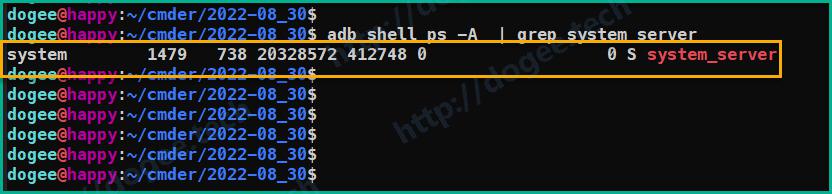
接一条
awk '{print $2}'命令,输出进程的ID号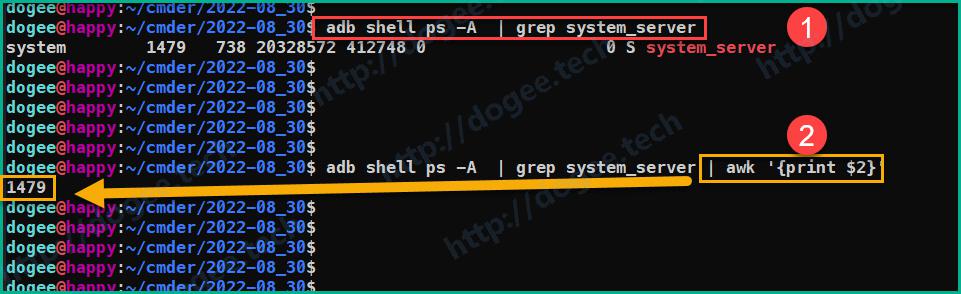
再使用
xargs -I {} adb logcat -b --pid={},打印出这个进程的专属日志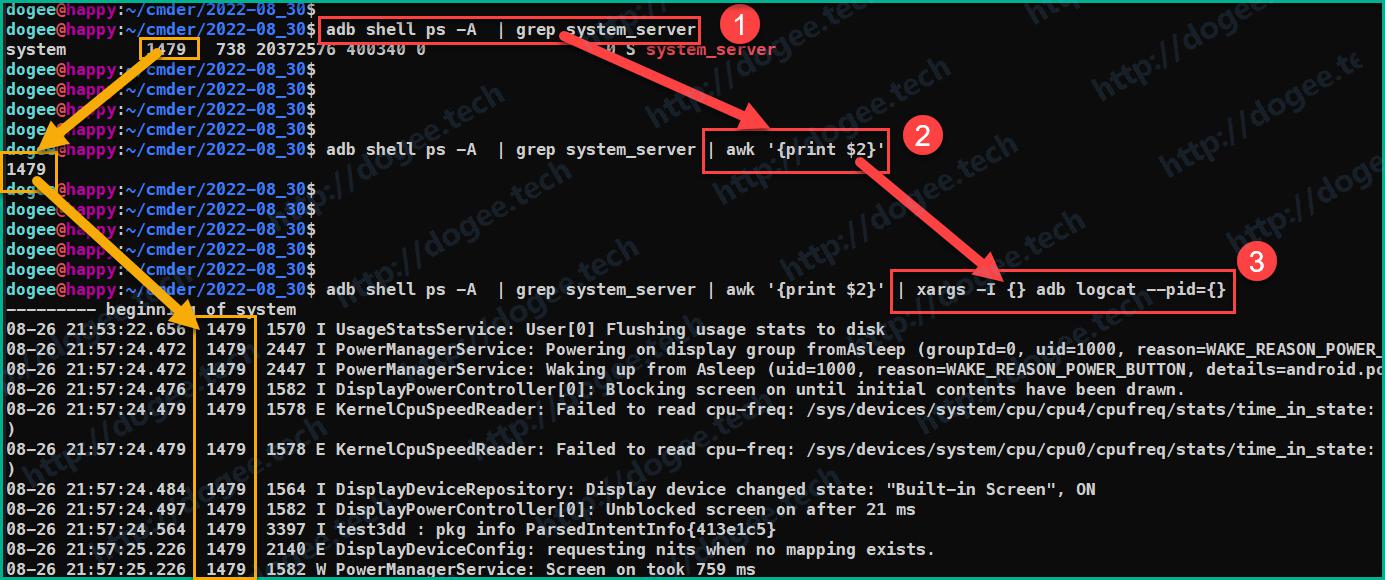
当然也不排除有更好的办法, 这边只是就我自己的一个经验做分享。
技巧点:awk+print命令,awk+printf命令,awk + grep + xargs + logcat过滤日志
5.正则表达式
正则表达式的部分,网上有很多的教程:
一般工作中我比较常用到的是通配符匹配,字符串匹配,通配符匹配中需要区分.和*。
- .:匹配除换行符 \n 之外的任何单字符。
- *:匹配前面的子表达式零次或多次。
匹配所有字符:[.]*
需要特别注意的是在UltraEdit编辑器中,正则表达式有两种,一种是UltraEdit的,一种是标准的,其中UltraEdit的表达式略微有些不同。