目的
如何利用已有模型,针对现有数据集进行retrain,在短时间内获得还不错的模型。
本文是从工程角度来阐述整个配置/运行/训练的过程,至于推导原理和模型介绍等会另外开文。
本文是一篇基于工程实作的流水科普文,看完这篇文章,你会:
- 明白tensorflow retrain的大概原理
- 知道了一个叫做inception(感知)模型
- 大概了解了retrain为什么可以生效
- retrain一个模型大概需要做哪些事情
同时,你仍旧不会知道:
- 代码如何写
除非,你
- 把所有的链接都挨个点开看了一篇并且实作了一下
虚拟项目诉求
- 给定一段王者荣耀的游戏视频,从中判定出当前玩家操作的是哪个英雄。
这个需求在知乎上已经有人提出过,但并没有给出具体的工程过程。这边结合原作者的思路,一并整理。
知乎原文链接如下:识别王者英雄 - 一个 PM 的机器学习入门之旅
素材收集
- 视屏本身就是一堆图片的集合而已,因此,对于视频的识别,我们可以转换为图片的识别
- 从一些视屏网站入手,或者自己在玩王者荣耀的时候尝试录屏,就可以得到很多高清视屏文件
通过ffmpeg,可以非常方便的把视频文件中的iframe抽出来,转换成jpeg保存
ffmpeg -i test.mp3 -r 1 -q:v 2 -ss 100 -f image2 pic-%03d.jpeg
ffmpeg常用命令:链接经过ffmpeg的转换,我们就拿到了一大批jpeg的原图,至于后面要怎么处理,则依据不同需求而定。
实操过程
模型训练
目前机器学习的训练,一般分为模型创建和模型训练两个步骤。
其中模型创建的部分,可以根据已有模型结构(论文)作为参考,或者是自己独创。
模型训练的部分,根据之前的模型结构,分为retrain和train:
前者是基于已经训练好的模型(固化的参数),增加一些新的层,在新的数据集上进行训练,从而得到新的模型。
后者则是完全重头开始训练,一般来说,同样的模型,在数据足够多,训练足够充分的情况下,效果比第一种好。
这里我们采取第二种方式,即retrain的方式,而选取的base model是google的inception v3
另外可以提一下,关于retrain的方式,tensorflow org也有详细的指导:链接
插一句,inception模型一般被翻译为“感知模型”,是基于ImageNet-2012的数据集进行训练的一个分类模型,论文地址,针对ImageNet-2012,训练后的模型top5的错误率在3.46%,可以说是非常恐怖的存在了。
言归正传,我们先需要获取到inception v3的模型以及固化的参数。
Inception v3的地址:传送门
解压后我们会得到下面几个文件:
- classify_image_graph_def.pb
- imagenet_synset_to_human_label_map.txt
- imagenet_2012_challenge_label_map_proto.pbtxt
其中比较重要的是classify_image_graph_def.pb,这个文件是inception v3模型在ImageNet上经过训练后,模型中各个参数固化以后生成的结果,用一句大白话,这个文件既包含了整个模型的结构,也包含了整个模型中各个层的变量值。
而imagenet_synset_to_human_label_map.txt其实就是index <-> class的一个转换表而已,对于我们识别英雄来说,并没有什么帮助。
工程实作
基于现有的inception v3固化模型,实作上,我们通过去掉原本模型最后的一层全连接层,即classify层,然后加入一层我们自己定义的全连接层,节点的数量就是我们需要分类的个数。
这样做可以成功的理论意义是:
inception中间的那些层,其实是在帮助提取图片中的各种feature。
第一层可能提取了一些比较底层的信息,比如毛孔,细胞等等的
第二层则是把第一层的数据做了个组合,出现了毛发,斑点等信息
…..
简单来说,越底层的feature就越抽象,越往上就越具象,最后一层则是根据这些具象的特征做了分类
因此,当我们去掉inception v3模型的最后一层,其实只是去掉了最后的分类,但是之前提取feature的那些节点,仍旧是被保留了下来,在新的模型上,仍旧是按照之前的规则去提取了feature,然后再根据不同feature做组合,得出新的分类结果
这一块有一点trick的味道,以上是我的理解。
继续回到Inception V3模型,在使用Inception V3模型上有一点需要注意:
- 整个模型的input节点:DecodeJpeg/contents:0
- 最后一层全连接层之上的那一次,被称为“瓶颈层”(bottleneck):pool_3/_reshape:0
这里的input输入图片的raw data,然后经过一系列计算,从瓶颈层输出的则是归一化以后的各种特征值
针对每一张图片,这个特征值是不会变的,但是由于在实际操作中,我们在每次epoch训练都会读取一次每张图片,为了节省计算的时间,建议先把所有图片的bottleneck计算出来。而这些bottleneck,其实就是我们自己新增加的那一层(或者那几层)的输入数据。
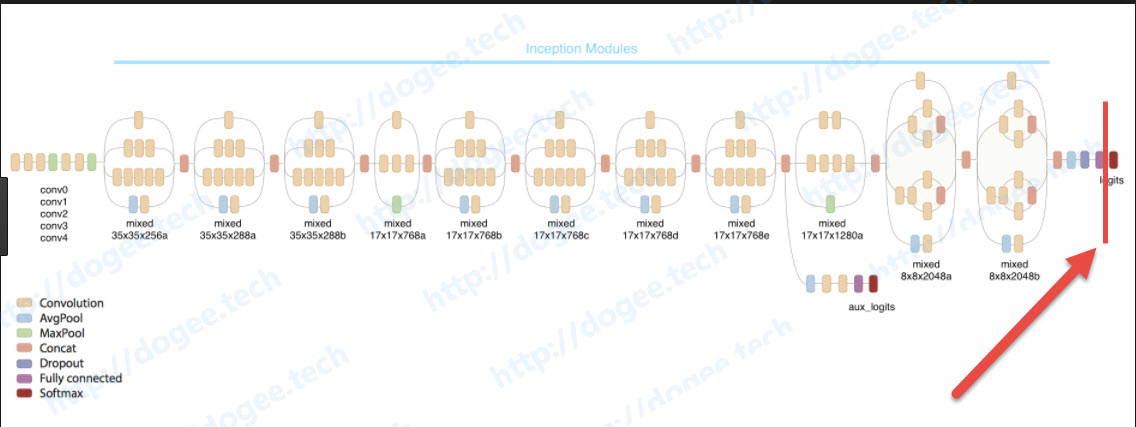
网上随便找了一张旧版的inception模型图解,红线的左边就是我们所谓的“瓶颈层”(bottleneck),从这边切开,后面的logits即是所谓的分类层。
至于要引入的那一层有什么特殊的设定,其实在我看来并没有什么难度,直接引入一个带有负反馈的全连接层,基本上效果就不错了。(使用14000张图片进行了10个epoch的训练,基本上识别率可以达到80%)
这边的retrain,可以采取官方推荐的做法,也就是通过:
tensorflow/examples/image_retraining/retrain
我这边是自己编写py文件,通过载入了原来的模型,然后再依次获取input,bottleneck,再放到tf的session中运行来做的,两种做法都有各自的利弊,前者更方便,后者更灵活。
嘴炮小结
上面的所有一切都是嘴炮编码,是我在实际工作中的流水账。
而其实在实际工作中,对于识别英雄的图片选型,视频到图片的转换,转换后图片的筛选,图片区域的裁减,每个环节都需要投入一定的精力和时间去完成。
最后,对于英雄的识别,我采用了识别王者英雄 - 一个 PM 的机器学习入门之旅里面的做法,即使用识别第二技能去关联特定英雄,这是一种投机取巧的办法,当然也存在很大问题,比如,技能可以自由换位,所以,训练就失效了。
真实的故事
- 从各大视频网站爬了一些HD视频
- 通过FFMPEG把能转换的视屏文件中的iframe抽出来,保存为jpeg
- 对所有的jpeg文件进行缩放,比如统一到尺寸1280x720
- 删除不必要的图片,比如loading界面,购买装备的界面等等无法看到英雄技能的图片
- 裁减出二技能的区域,重新保存为带有标记的jpeg,比如XXX英雄_000011.jpeg
- 把所有整理完&带有标记的图片送入阉割后的inception模型进行学习,得到bottleneck值
- 把这些bottleneck值送入新的分类器进行学习
- 链接“阉割后的inception”与“新的分类器”,并固化所有的训练参数
恭喜通关,我们终于拿到了我们自己的模型
mobile porting
当我们拿到了训练后固化参数的“XXXX.pb”模型后,就可以兴高采烈的往mobile设备上移植了。
网上比较有名的文章是这篇:TensorFlow for mobile poets,它有很详细的说明了要怎么做。
其中比较重要的是optimize_for_inference:
- 通过optimize_for_inference优化我们训练完的模型
注意,由于移动设备上不支持Decode_jpeg操作符,所以poets示范中的优化模型,是从Mul节点开始的
然后这个模型就可以直接丢到mobile设备上去使用了,当然,在使用这个模型之前,我们还需要透过tensorflow编译一下对应的jar包,so库等等,这些细节可以参考:Android引入TF的准备工作
而那些activity要怎么写,模型要如何加载等问题,可以参考:ClassifierActivity.java
以上就是整个项目的实作流程了,整个过程中其实最繁琐的部分是数据的获取和处理,其实编写网络所花费的时间远远不及数据预处理花的多。
对于网络而言,训练和后期fine-tune则是重中之重。
最后,在往移动端移植的时候,由于需要用到一些tensorflow的工具,在tensorflow的源码编译和交叉编译上,也耗费了不少时间,总的来说,坑多多,收获也多多。