摘要
| 摘要 | Abstract | |
|---|---|---|
| 在自然图片中识别任意长度的文字是一个难题。在本文,我们提供了一种方法,可以解决这个难题中的一个子问题:识别街景照片中的数字。通常意义上,解决这个问题的一般方法是三个步骤,定位,分割以及识别。在本文,我们提出了一个统一的方法,即通过深度卷积神经网络直接基于图像像素来做处理,从而整合了这三个步骤,我们采用了DistBee来实现高质量图像的大型分布式神经网络,并且发现这种方法的性能会随着网络深度的加深而增加。在我们架构中,拥有11个隐藏层的网络出现了最好的准确率。我们在公开的SVHN数据集上进行了这个测试,在识别完整街道号牌的准确率上达到了96%以上。同时,我们还准备在更难的数据集上进行这项测试,这个数据集包含了千万条街道号牌,我们最终获取了90%以上的准确率。为了进一步探索模型的实用性,我们将其用于reCAPTCHA的验证码识别系统。reCAPTCHA主要是通过扭曲的文本,来区分操作者是真实人类,还是机器,目前reCAPTCHA被认为是最安全的反图灵测试之一。本模型在reCAPTCHA上对最难的几个类别上,获得了98%的识别准确率,因此,我们认为在特定的操作阈值下,该系统的识别率与真实人类相差无几,甚至有些特定场景还超过了人类。 | Recognizing arbitrary multi-character text in unconstrained natural photographs is a hard problem. In this paper, we address an equally hard sub-problem in this domain viz. recognizing arbitrary multi-digit numbers from Street View imagery. Traditional approaches to solve this problem typically separate out the localiza- tion, segmentation, and recognition steps. In this paper we propose a unified ap- proach that integrates these three steps via the use of a deep convolutional neu- ral network that operates directly on the image pixels. We employ the DistBe- lief (Dean et al., 2012) implementation of deep neural networks in order to train large, distributed neural networks on high quality images. We find that the per- formance of this approach increases with the depth of the convolutional network, with the best performance occurring in the deepest architecture we trained, with eleven hidden layers. We evaluate this approach on the publicly available SVHN dataset and achieve over 96% accuracy in recognizing complete street numbers. We show that on a per-digit recognition task, we improve upon the state-of-the- art, achieving 97.84% accuracy. We also evaluate this approach on an even more challenging dataset generated from Street View imagery containing several tens of millions of street number annotations and achieve over 90% accuracy. To further explore the applicability of the proposed system to broader text recognition tasks, we apply it to transcribing synthetic distorted text from a popular CAPTCHA ser- vice, reCAPTCHA. reCAPTCHA is one of the most secure reverse turing tests that uses distorted text as one of the cues to distinguish humans from bots. With the proposed approach we report a 99.8% accuracy on transcribing the hardest cat- egory of reCAPTCHA puzzles. Our evaluations on both tasks, the street number recognition as well as reCAPTCHA puzzle transcription, indicate that at specific operating thresholds, the performance of the proposed system is comparable to, and in some cases exceeds, that of human operators. |
重点信息
- recognizing arbitrary multi-digit numbers
- ocaliza- tion, segmentation, and recognition steps
- integrates these three steps via the use of a deep convolutional neu- ral network that operates directly on the image pixels.
- with eleven hidden layers
- SVHN
- reCAPTCHA
1 . 简介
| 简介 | Introduction |
|---|---|
| 识别在街道拍摄的照片中的多位数字是现代地图制作的重要组成部分。 谷歌街景图像的一个典型例子是谷歌的街景图像,其中包含数亿个地理位置360度全景图像。 从地理位置的像素块中自动转录地址编号并将转录的编号与已知的街道地址相关联的能力有助于精确地确定其所代表的建筑物的位置。 | Recognizing multi-digit numbers in photographs captured at street level is an important component of modern-day map making. A classic example of a corpus of such street level photographs is Google’s Street View imagery comprised of hundreds of millions of geo-located 360 degree panoramic images. The ability to automatically transcribe an address number from a geo-located patch of pixels and associate the transcribed number with a known street address helps pinpoint, with a high degree of accuracy, the location of the building it represents. |
| 更广泛地说,识别照片中的数字是光学字符识别社区感兴趣的问题。 虽然在像文档处理这样的受限域上进行OCR的研究很充分,但对照片中的任意多字符文本识别仍然是非常具有挑战性的。由于大量的字体,颜色,样式,方向和字符排列,以及文本的视觉外观的广泛变化,都增加了这种识别的困难。另外,还由于光照,阴影,镜面反射和遮挡等环境因素以及分辨率,运动和焦点模糊等图像采集因素,导致了这一问题的进一步复杂化。 | More broadly, recognizing numbers in photographs is a problem of interest to the optical character recognition community. While OCR on constrained domains like document processing is well studied, arbitrary multi-character text recognition in photographs is still highly challenging. This difficulty arises due to the wide variability in the visual appearance of text in the wild on account of a large range of fonts, colors, styles, orientations, and character arrangements. The recognition problem is further complicated by environmental factors such as lighting, shadows, specularities, and occlusions as well as by image acquisition factors such as resolution, motion, and focus blurs. |
| 在本文中,我们重点关注从街景全景识别多位数字。 虽然这减少了需要识别的字符的空间,但是上面列出的复杂性仍然适用于这个子域。 由于这些复杂性,解决这个问题的传统方法通常将定位,分割和识别步骤分开。 | In this paper, we focus on recognizing multi-digit numbers from Street View panoramas. While this reduces the space of characters that need to be recognized, the complexities listed above still apply to this sub-domain. Due to these complexities, traditional approaches to solve this problem typically separate out the localization, segmentation, and recognition steps. |
| 在本文中,我们提出了一个统一的方法,通过使用直接在图像像素上运行的深度卷积神经网络来整合这三个步骤。 这个模型配置了多个隐藏层(我们最好的配置有11层,但是我们的实验表明更深的架构可能会获得更好的精度,但是收益递减),所有的都是前馈连接。我们采用DistBelief来实现这些大规模的深度神经网络。 | In this paper we propose a unified approach that integrates these three steps via the use of a deep convolutional neural network that operates directly on the image pixels. This model is configured with multiple hidden layers (our best configuration had eleven layers, but our experiments suggest deeper architectures may obtain better accuracy, with diminishing returns), all with feedforward connections. We employ DistBelief to implement these large-scale deep neural networks. |
| 我们已经在公开可用的街景门牌号码(SVHN)数据集上评估了这种方法,并且在识别街道号码方面的准确率达到了96%以上。实验表明,在每个数字的识别任务,使用最新的模型,我们可以达到97.84%的准确性。同时,我们还对街景视图图像生成的更具挑战性的数据集进行了评估,该数据集包含数千万个街道号码注释,并且准确度达到90%以上。我们的评估进一步表明,在特定的操作阈值下,所提出的系统的性能与人类操作员的性能相当。迄今为止,我们的系统已经帮助我们从全球的街景图像中提取近1亿条街道号码。 | We have evaluated this approach on the publicly available Street View House Numbers (SVHN) dataset and achieve over 96% accuracy in recognizing street numbers. We show that on a per- digit recognition task, we improve upon the state-of-the-art and achieve 97.84% accuracy. We also evaluated this approach on an even more challenging dataset generated from Street View imagery containing several tens of millions of street number annotations and achieve over 90% accuracy. Our evaluations further indicate that at specific operating thresholds, the performance of the proposed system is comparable to that of human operators. To date, our system has helped us extract close to 100 million street numbers from Street View imagery worldwide. |
| 显然,上面列出的街景数字识别是真实世界中自然文字的问题,但在另一方面,故意扭曲的CAPTCHA文字也是一个难题。CAPTCHA是反向图灵测试,旨在使用扭曲的文本区分人和运行自动文本识别软件的机器。 这些基于文本的估计扭曲/失真被用来增加文本视觉外观的变化,从而增加识别难度。为了评估我们模型的普适性,我们将其应用于从网络上广泛使用的CAPTCHA服务之一reCAPTCHA,用来尝试解决CAPTCHA问题。实验表明,对于reCAPTCHA中最难的问题,我们可以达到99.8%的准确性。 | While the challenges listed above for numbers in Street View data can be considered to be real world, natural variabilities in text, another class of data where text is deliberatly distorted syntheti cally is in CAPTCHA puzzles. CAPTCHAs are reverse turing tests designed to use distorted text to distinguish humans and machines running automated text recognition software. Synthetic dis- tortions on these text based puzzles is used to increase variability in the visual appearance of the text, thus increasing transcription difficulty. In order to evaluate the general applicability of the peo- posed approach to the broader task of recognizing arbitrary text, we applied it to the task of solving CAPTCHA puzzles from reCAPTCHA, one of the widely used CAPTCHA service on the internet. We show that we are able to achieve a 99.8% accuracy on the hardest reCAPTCHA puzzle. |
| 本文的主要贡献是:(a)一个统一的模型来定位,分割和识别街道照片中的多位数字(b)一种新的输出层,提供序列的条件概率模型(c)经验表明,更深的网络层次会拥有更好的表现形式(d)在reCAPTCHA图像的harderst类别上应用所提出的模型的结果,以达到99.8%的识别准确性(e)在特定的操作阈值下达到人类水平的表现。 | The key contributions of this paper are: (a) a unified model to localize, segment, and recognize multi- digit numbers from street level photographs (b) a new kind of output layer, providing a conditional probabilistic model of sequences (c) empirical results that show this model performing best with a deep architecture (d) results of applying proposed model on the harderst category of reCAPTCHA images to achieve 99.8% transcription accuracy (e) reaching human level performance at specific operating thresholds. |
重点信息
- OCR
- fonts, colors, styles, orientations, and character arrangements.
- lighting, shadows, specularities,occlusions,resolution, motion, focus blurs
- focus on recognizing multi-digit numbers from Street View panoramas.
- localization, segmentation, and recognition steps.
- operates directly on the image pixels.
- multiple hidden layers (our best configuration had eleven layers, but our experiments suggest deeper architectures may obtain better accuracy, with diminishing returns)
- (a) a unified model
- (b) a new kind of output layer,
- (e) reaching human level performance
2 . 相关工作
| 相关工作 | Related work |
|---|---|
| 卷积神经网络是神经网络一系列拥有共享参数的神经元。像大多数神经网络一样,它们包含几个滤波层,每一层对矢量输入应用仿射变换,然后再做非线性变换。在卷积网络的情况下,仿射变换可以被实现为离散卷积而不是完全一般的矩阵乘法。这使得卷积网络在计算上是高效的,使得它们能够扩展成大的图像。它也建立了平移到模型中的换算(换句话说,如果图像向右移动一个像素,则卷积的输出也向右移动一个像素;即平移不变性)。基于图像的卷积网络通常使用池化层,池化层的目的是通过一个响应来总结这一片区域的特征。池化层可以是最大池,平均池,L2正则池等等。这些池化层有助于网络对输入的小型数据的健壮性。 | Convolutional neural networks (Fukushima, 1980; LeCun et al., 1998) are neural networks with sets of neurons having tied parameters. Like most neural networks, they contain several filtering layers with each layer applying an affine transformation to the vector input followed by an elementwise non-linearity. In the case of convolutional networks, the affine transformation can be implemented as a discrete convolution rather than a fully general matrix multiplication. This makes convolutional networks computationally efficient, allowing them to scale to large images. It also builds equivari- ance to translation into the model (in other words, if the image is shifted by one pixel to the right, then the output of the convolution is also shifted one pixel to the right; the two representations vary equally with translation). Image-based convolutional networks typically use a pooling layer which summarizes the activations of many adjacent filters with a single response. Such pooling layers may summarize the activations of groups of units with a function such as their maximum, mean, or L2 norm. These pooling layers help the network be robust to small translations of the input. |
| 计算能力的提升,训练集大小的增加,以及诸如使用分段线性单元的算法改进和遗忘率的引入,极大改进了卷积神经网络的性能,从而在物体识别领域,使用卷积神经网络已经获得了极大的成功。 | Increases in the availability of computational resources, increases in the size of available training sets, and algorithmic advances such as the use of piecewise linear units (Jarrett et al., 2009; Glorot et al., 2011; Goodfellow et al., 2013) and dropout training (Hinton et al., 2012) have resulted in many recent successes using deep convolutional neural networks. Krizhevsky et al. (2012) obtained dramatic improvements in the state of the art in object recognition. Zeiler and Fergus (2013) later improved upon these results. |
相关工作 |Related work |
—-|——|
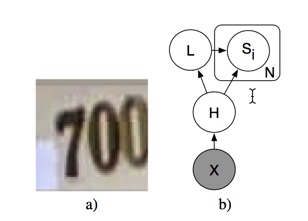
图1:a)要被识别的示例输入图像。该图像的正确输出是“700”。 b)我们的序列转录模型的图形模型结构,使用区域标记描述来表示多个Si。 请注意,X和H之间的关系是确定性的。 从L到Si的边是可选的,这会帮助我们了解到,对于大于长度L的数字Si,P(S|X)是没有意义的。|Figure 1: a) An example input image to be transcribed. The correct output for this image is “700”. b) The graphical model structure of our sequence transcription model, depicted using plate nota- tion (Buntine, 1994) to represent the multiple Si. Note that the relationship between X and H is deterministic. The edges going from L to Si are optional, but help draw attention to the fact that our definition of P(S | X) does not query Si for i > L.
在Google等大型数据集上,过度拟合并不是问题,增加网络规模会提高培训和测试的准确性。 为此,Dean等人 (2012)开发了DistBelief,一种可扩展的深度神经网络实现,其中包括对卷积网络的支持。 我们使用这个基础设施作为本文实验的基础。|On huge datasets, such as those used at Google, overfitting is not an issue, and increasing the size of the network increases both training and testing accuracy. To this end, Dean et al. (2012) de- veloped DistBelief, a scalable implementation of deep neural networks, which includes support for convolutional networks. We use this infrastructure as the basis for the experiments in this paper.
以前卷积神经网络主要用于对输入图像中单个对象做识别等应用。在某些情况下,它们被用作解决更复杂任务的系统组件。 比如Girshick等人(2013)使用卷积神经网络作为物体检测和定位的系统的特征提取器。然而,整个系统比负反馈训练的神经网络大太多,并且具有处理很多机制的特殊代码,例如提出候选目标区域。 Szegedy等人(2013年)表明,神经网络可以学习输出heatmap,后处理,以解决目标定位问题。在我们的工作中,我们采用了类似的方法,但后处理较少,并且要求输出是一个有序的序列,而不是一个无序的检测对象列表。Alsharif和Pineau(2013)使用卷积最大值网络(Goodfellow等,2013)提供许多条件概率分布,使用HMM来从图像转录文本。在这项工作中,我们提出解决类似的任务涉及到定位和分割,但我们建议在学习的卷积网络内完成整个任务。在我们的方法中,系统的独立组件不需要提出候选分割或提供更高级别的图像模型。|Convolutional neural networks have previously been used mostly for applications such as recog- nition of single objects in the input image. In some cases they have been used as components of systems that solve more complicated tasks. Girshick et al. (2013) use convolutional neural networks as feature extractors for a system that performs object detection and localization. However, the system as a whole is larger than the neural network portion trained with backprop, and has special code for handling much of the mechanics such as proposing candidate object regions. Szegedy et al. (2013) showed that a neural network could learn to output a heatmap that could be post-processed to solve the object localization problem. In our work, we take a similar approach, but with less post-processing and with the additional requirement that the output be an ordered sequence rather than an unordered list of detected objects. Alsharif and Pineau (2013) use convolutional maxout networks (Goodfellow et al., 2013) to provide many of the conditional probability distributions used in a larger model using HMMs to transcribe text from images. In this work, we propose to solve similar tasks involving localization and segmentation, but we propose to perform the entire task completely within the learned convolutional network. In our approach, there is no need for a separate component of the system to propose candidate segmentations or provide a higher level model of the image.
重点信息
- maximum, mean, or L2 norm.
- Increases in the availability of computational resources, increases in the size of available training sets
- algorithmic advances
- dropout training
- Si,P(S | X)
- Girshick et al. (2013) use convolutional neural networks as feature extractors for a system that performs object detection and localization.
- output be an ordered sequence
3 . 问题描述
| 问题描述 | Problem description |
|---|---|
| 街道号码识别是一种特殊的序列识别。给定一个图像,任务是确定图像中的数字。 见图1a中的一个例子。 要识别的号码是一个数字序列,s = s1,s2,…。。。 ,sn。 当确定数字识别的准确性时,我们需要输入图像的数字的长度n和序列的每个元素si被正确预测。对于这个任务而言,没有“部分正确”的概念,这是因为为了制作地图,如果整个街道号码被正确识别,才能在地图上找到建筑物。 | Street number transcription is a special kind of sequence recognition. Given an image, the task is to identify the number in the image. See an example in Fig. 1a. The number to be identified is a sequence of digits, s = s1 , s2 , . . . , sn . When determining the accuracy of a digit transcriber, we compute the proportion of the input images for which the length n of the sequence and every element si of the sequence is predicted correctly. There is no “partial credit” for getting individual digits of the sequence correct. This is because for the purpose of making a map, a building can only be found on the map from its address if the whole street number was transcribed correctly. |
| 如果要建立一个地图,至少要达到人类水平的准确性是非常重要的。使用地图的用户被引导到错误的位置,这会浪费用户的时间,所以必须尽量减少输入到地图中的不正确的识别数量。因此,我们不可能录入每一个识别的结果。由于每个街道号码可能已被多次拍摄,我们在地图上放置的建筑物的比例很可能大于我们可以录制的图像的比例。因此,我们主张在一定准确度水平的基础上评估这一任务,而不仅仅是评估系统的总体准确度。为了评估覆盖范围,系统必须返回一个置信度值,比如最可能的预测的概率是正确的。然后可以丢弃低于某个置信度阈值的识别。覆盖范围被定义为未被丢弃的输入的比例。某个特定准确度水平的覆盖范围是选择置信度阈值以达到所需的准确度水平时的覆盖范围。对于制图目的,我们主要关注覆盖率达到98%或更高,因为这大致对应于人类的准确性。 | For the purpose of building a map, it is extremely important to have at least human level accuracy. Users of maps find it very time consuming and frustrating to be led to the wrong location, so it is essential to minimize the amount of incorrect transcriptions entered into the map. It is, however, acceptable not to transcribe every input image. Because each street number may have been pho- tographed many times, it is still quite likely that the proportion of buildings we can place on the map is greater than the proportion of images we can transcribe. We therefore advocate evaluating this task based on the coverage at certain levels of accuracy, rather than evaluating only the total degree of accuracy of the system. To evaluate coverage, the system must return a confidence value, such as the probability of the most likely prediction being correct. Transcriptions below some confidence threshold can then be discarded. The coverage is defined to be the proportion of inputs that are not discarded. The coverage at a certain specific accuracy level is the coverage that results when the confidence threshold is chosen to achieve that desired accuracy level. For map-making purposes, we are primarily interested in coverage at 98% accuracy or better, since this roughly corresponds to human accuracy. |
| 使用置信度阈值允许我们随着时间的推移增量地改进地图。如果我们开发的系统总体精度较差,但在一定的阈值下具有良好的准确性,我们就可以制作部分覆盖的地图,然后在未来获得更精确的识别系统时提高覆盖率。我们也可以通过自动化系统使用置信阈值来尽可能多地完成工作,其余的则使用更昂贵的方法,比如雇用人工操作员来识别剩下的难题。 | Using confidence thresholding allows us to improve maps incrementally over time–if we develop a system with poor accuracy overall but good accuracy at some threshold, we can make a map with partial coverage, then improve the coverage when we get a more accurate transcription system in the future. We can also use confidence thresholding to do as much of the work as possible via the automated system and do the rest using more expensive means such as hiring human operators to transcribe the remaining difficult inputs. |
| 街道号转录问题的一个特殊性质是序列是有限长度的。很少有街道号码包含五位以上的数字,所以我们可以使用假定序列长度n最多是某个常数N的模型,N = 5。作出这种假设的系统应该能够识别违反这一假定的情况,并拒绝返回一个识别,以便长度大于N的少数街道数字在被转录为长度N后没有被错误地添加到地图中。(换句话说,如果返回的某个识别的置信率太低,那么我们就认为没有识别,从而拒绝这个识别结果) | One special property of the street number transcription problem is that the sequences are of bounded length. Very few street numbers contain more than five digits, so we can use models that assume the sequence length n is at most some constant N, with N = 5 for this work. Systems that make such an assumption should be able to identify whenever this assumption is violated and refuse to return a transcription so that the few street numbers of length greater than N are not incorrectly added to the map after being transcribed as being length N. (Alternately, one can return the most likely sequence of length N, and because the probability of that transcription being correct is low, the default confidence thresholding mechanism will usually reject such transcriptions without needing special code for handling the excess length case) |
重点信息
- which the length n of the sequence and every element si of the sequence is predicted correctly.
- based on the coverage at certain levels of accuracy, rather than evaluating only the total degree of accuracy of the system.
4 . 实作方法
| 实作方法 | Methods | |||||
|---|---|---|---|---|---|---|
| 我们的方法是训练给定图像序列的概率模型。设S代表输出序列,X代表输入图像。我们的目标是通过最大化训练集上的log P(S \ | X)来学习P(S \ | X)的模型。 | Our basic approach is to train a probabilistic model of sequences given images. Let S represent the output sequence and X represent the input image. Our goal is then to learn a model of P (S | X ) by maximizing log P (S | X ) on the training set. | |
| 为了获得S,我们将S定义为N个随机变量S1,…,的集合。其中Sn代表序列元素和L代表序列长度。我们假定分开的数字的身份是相互独立的,所以特定序列的概率为s = s1,…,sn的结果是: | To model S, we define S as a collection of N random variables S1 , . . . , SN representing the elements of the sequence and an additional random variable L representing the length of the sequence. We assume that the identities of the separate digits are independent from each other, so that the probability of a specific sequence s = s1 , . . . , sn is given by | |||||
| 公式 | P(S=s\ | X)=P(L=n\ | X)P(S1 =s1 \ | X)P(S2 =s2 \ | X)…P(Sn =sn \ | X) |
| 这个模型可以被扩展,也就是我们假定输出的序列长度为L,如果长度大于了L,那么就是无效的。为了检测这种情况,我们只需添加一个代表这个结果的附加值L. | This model can be extended to detect when our assumption that the sequence has length at most N is violated. To allow for detecting this case, we simply add an additional value of L that represents this outcome. | |||||
| 上述变量中的每一个都是独立的,并且当应用于街道号识别问题时,每个数字都有少量的可能值:L只具有7个值(0,…,5和“大于5”),并且每个数字变量有10个可能的值。这意味着使用softmax分类器来表示每个分类器是可行的,该分类器接收卷积神经网络从X中提取的输入特征。我们可以把这些特征表示为一个随机变量H,其值是给定X的确定性。在这个模型中,P(S \ | X)= P(S \ | H)。 网络结构的图形模型描述见图1b。 | Each of the variables above is discrete, and when applied to the street number transcription problem, each has a small number of possible values: L has only 7 values (0, . . . , 5, and “more than 5”), and each of the digit variables has 10 possible values. This means it is feasible to represent each of them with a softmax classifier that receives as input features extracted from X by a convolutional neural network. We can represent these features as a random variable H whose value is deterministic given X. In this model, P(S \ | X) = P(S \ | H). See Fig. 1b for a graphical model depiction of the network structure. | |
| 为了训练模型,可以使用随机梯度下降这样的通用方法,使训练集上的log P(S \ | X)最大化。 每个softmax模型(L和每个Si的模型)可以使用与训练单独的softmax层时完全相同的backprop学习规则,对于那些没有数字的部分,我们不需要做backprop。 测试时间,我们预测 | To train the model, one can maximize log P (S \ | X ) on the training set using a generic method like stochastic gradient descent. Each of the softmax models (the model for L and each Si) can use exactly the same backprop learning rule as when training an isolated softmax layer, except that a digit classifier softmax model backprops nothing on examples for which that digit is not present.At test time, we predict | |||
| 公式 | s = (l,s1,…,sl) = argmaxL,S1,…,SL logP(S \ | X) | ||||
| 这个argmax可以用线性时间来计算。每个字符的argmax可以独立计算。然后我们递增地累加每个角色的对数概率。对于每个长度l,完整的对数概率是由这个运行的字符对数概率和加上log P(l \ | x)给出的。 总运行时间是O(N)。 | This argmax can be computed in linear time. The argmax for each character can be computed independently. We then incrementally add up the log probabilities for each character. For each length l, the complete log probability is given by this running sum of character log probabilities, plus log P (l \ | x). The total runtime is thus O(N ). | |||
| 在预处理方面,我们会减掉图像的平均值(归一化),但是不会对图像做美白增强或者是对比度增强的操作 | We preprocess by subtracting the mean of each image. We do not use any whitening (Hyva ̈rinen et al., 2001), local contrast normalization (Sermanet et al., 2012), etc. |
重点信息
- P(S=s|X)=P(L=n|X)⇧ni=1P(Si =si |X).
- a random variable H whose value is deterministic given X. In this model, P(S | X) = P(S | H)
- stochastic gradient descent.
- preprocess by subtracting the mean of each image.
5 . 实验
| 实验 | Experiments |
|---|---|
| 1111 | In this section we present our experimental results. First, we describe our state of the art results on the public Street View House Numbers dataset in section 5.1. Next, we describe the performance of this system on our more challenging, larger but internal version of the dataset in section 5.2. We then present some experiments analyzing the performance of the system in section 5.4. |
5 . 1 基于公开数据集SVHN的实验
| 基于公开数据集SVHN的实验 | 5.1 Public Street View House Numbers dataset |
|---|---|
| 街景房屋号码(SVHN)数据集是一个包含大约200k街道号码的数据集,其中还标识出了每个数字的边框,共计约600k位。据我们所知,以前发表的所有作品都是个别数字,并试图识别这些数字。我们取而代之的是包含多个数字的原始图像,并重点同时识别它们。 | The Street View House Numbers (SVHN) dataset (Netzer et al., 2011) is a dataset of about 200k street numbers, along with bounding boxes for individual digits, giving about 600k digits total. To our knowledge, all previously published work cropped individual digits and tried to recognize those. We instead take original images containing multiple digits, and focus on recognizing them all simultaneously. |
| 我们按照以下方式预处理数据集,首先找到包含单个字符边界框的小矩形边界框。然后,我们在x方向和y方向上将该边界框扩展30%,将图像裁剪到边界框,并将裁剪大小调整为64 x 64像素。之后,我们从64×64像素的图像内的随机位置裁剪出54×54像素的图像。这意味着我们生成了每个训练样例的几个随机移位版本,以增加数据集的大小。没有这个数据增加,我们会失去大约半个百分点的准确性。由于图像中的字符数量不同,这引入了相当大的尺度变化性,对于单个数字的街道号码来说,数字填满了整个方块,与此同时,我们缩小5位数字的街道号码,以便可以让所有号码都被放到图片里。 | We preprocess the dataset in the following way – first we find the small rectangular bounding box that will contain individual character bounding boxes. We then expand this bounding box by 30% in both the x and the y direction, crop the image to that bounding box and resize the crop to 64 x 64 pixels. We then crop a 54 x 54 pixel image from a random location within the 64 x 64 pixel image. This means we generated several randomly shifted versions of each training example, in order to increase the size of the dataset. Without this data augmentation, we lose about half a percentage point of accuracy. Because of the differing number of characters in the image, this introduces considerable scale variability – for a single digit street number, the digit fills the whole box, meanwhile a 5 digit street number will have to be shrunk considerably in order to fit. |
| 我们最好的模型获得了96.03%的序列识别准确性。但这还不够准确,我们无法直接将地址数据库中的街道号码添加到地图上。在使用98%置信率的基础上,我们获得95.64%的准确率。由于98%的准确性是人类操作者的表现,这些转录是可接受的包括在地图中。我们鼓励今后在这个数据集上工作的研究人员以98%的准确度以及标准的准确性度量来发布覆盖率。最终,我们的系统达到了97.84%的字符级准确度。这比之前识别单个字符的网络的最好识别率97.53%稍微高了一点点。 | Our best model obtained a sequence transcription accuracy of 96.03%. This is not accurate enough to use for adding street numbers to geographic location databases for placement on maps. However, using confidence thresholding we obtain 95.64% coverage at 98% accuracy. Since 98% accuracy is the performance of human operators, these transcriptions are acceptable to include in a map. We encourage researchers who work on this dataset in the future to publish coverage at 98% accuracy as well as the standard accuracy measure. Our system achieves a character-level accuracy of 97.84%. This is slightly better than the previous state of the art for a single network on the individual character task of 97.53% (Goodfellow et al., 2013). |
| 在DistBelief中,使用10个副本大约需要六天时间来培训这个模型。对于上面报告的每个性能指标,确切的培训时间会有所不同。我们使用验证集分别为每个性能指标选择最佳停止点。 | Training this model took approximately six days using 10 replicas in DistBelief. The exact training time varies for each of the performance measures reported above–we picked the best stopping point for each performance measure separately, using a validation set. |
重点信息
- along with bounding boxes for individual digits,
- We instead take original images containing multiple digits, and focus on recognizing them all simultaneously.
- first we find the small rectangular bounding box that will contain individual character bounding boxes,
- expand this bounding box by 30%
- crop the image to that bounding box
- crop to 64 x 64 pixels
- crop a 54 x 54
- in order to increase the size of the dataset.
前方高能
| 基于公开数据集SVHN的实验 | 5.1 Public Street View House Numbers dataset |
|---|---|
| 我们最好的架构由八个卷积隐藏层,一个本地连接的隐藏层和两个密集连接的隐藏层组成。所有的连接都是前馈,并从一层到下一层(没有跳过连接)。第一个隐含层使用maxout(每个单位有三个过滤器),而其他隐含层则使用Relu)。每层中每个空间位置的单元数量对于前四层为[48,64,128,160],对于所有其他本地连接层为192。完全连接的层包含3072个单位。每个卷积层包括max池化和归一化。max池化窗口大小为2 x 2.步幅在每一层交替变换,分别为2和1,以便一半的层不会减少表示的空间大小。所有卷积在输入上使用零填充以维持原尺寸。归一化的窗口大小为3x3。所有的卷积核的大小是5×5。所有的隐藏层都会用到遗忘率,但是输入层不应该使用。 | Our best architecture consists of eight convolutional hidden layers, one locally connected hidden layer, and two densely connected hidden layers. All connections are feedforward and go from one layer to the next (no skip connections). The first hidden layer contains maxout units (Goodfellow et al., 2013) (with three filters per unit) while the others contain rectifier units (Jarrett et al., 2009; Glorot et al., 2011). The number of units at each spatial location in each layer is [48, 64, 128, 160] for the first four layers and 192 for all other locally connected layers. The fully connected layers contain 3,072 units each. Each convolutional layer includes max pooling and subtractive normalization. The max pooling window size is 2 x 2. The stride alternates between 2 and 1 at each layer, so that half of the layers don’t reduce the spatial size of the representation. All convolutions use zero padding on the input to preserve representation size. The subtractive normalization operates on 3x3 windows and preserves representation size. All convolution kernels were of size 5 x 5. We trained with dropout applied to all hidden layers but not the input. |
高能退去
5 . 2 基于内部街景数据的实验
| 基于内部街景数据的实验 | 5.2 Internal Street View data |
|---|---|
| 在内部,我们有一个包含数千万转录街道数据的数据集。但是在这个数据集中,我们并没有标记出数字的标记狂。因此,我们使用自动化方法(超出本文的范围)来估计每个门牌号码的位置,然后裁剪到门牌号码周围的128×128像素区域。我们并没有重新调整图像,因为我们不知道房子号码的范围。这意味着网络必须比我们使用公共SVHN时更强大的健壮性。在这个数据集上,网络也必须本地化房屋识别到整个门牌号码,而不是仅仅局部化每个房屋号码中的数字。另外,因为在这个设置中训练集是较大的,所以我们不需要用随机偏移来增加数据。 | Internally, we have a dataset with tens of millions of transcribed street numbers. However, on this dataset, there are no ground truth bounding boxes available. We use an automated method (beyond the scope of this paper) to estimate the centroid of each house number, then crop to a 128 x 128 pixel region surrounding the house number. We do not rescale the image because we do not know the extent of the house number. This means the network must be robust to a wider variation of scales than our public SVHN network. On this dataset, the network must also localize the house number, rather than merely localizing the digits within each house number. Also, because the training set is larger in this setting, we did not need augment the data with random translations. |

基于内部街景数据的实验 |5.2 Internal Street View data |
—-|——|
图2:来自内部街道号码数据集,这些数字很难被识别,但我们做到了。此数据集中的一些挑战,包括对角线或垂直布局,错误使用了“-”,阴影,他遮,模糊。|Figure 2: Difficult but correctly transcribed examples from the internal street numbers dataset. Some of the challenges in this dataset include diagonal or vertical layouts, incorrectly applied blurring from license plate detection pipelines, shadows and other occlusions.
这个数据集很难处理,因为它来自更多的国家(超过12个),有的街道号码没有数字,而数据本身的标注也存在着问题。参见图2,上面是来自这个数据集的困难输入的一些示例,我们的系统能够正确地识别,而图3则展示了一些错误的识别结果。|This dataset is more difficult because it comes from more countries (more than 12), has street num- bers with non-digit characters and the quality of the ground truth is lower. See Fig. 2 for some examples of difficult inputs from this dataset that our system was able to transcribe correctly, and Fig. 3 for some examples of difficult inputs that were considered errors.
我们在这个更具挑战性的数据集上获得了91%的整体序列识别的准确性。使用置信度阈值的话,我们能够以83%的覆盖率获得99%的准确率,或以89%的覆盖率获得98%的准确度。在这个任务中,由于大量的训练数据,我们没有看到像SVHN看到的显着的过度拟合,所以我们没有使用dropout,使用dropout倾向于增加训练时间,我们最大的模型已经非常昂贵的训练。我们也没有使用maxout单位。所有隐藏的单位都是Relu。对于这个数据集,我们最好的架构类似于公共数据集的最佳架构,除了我们只使用五个卷积层而不是八个。(我们还没有尝试在这个数据集上使用八个卷积层;八层可能获得稍好的结果,但是具有五个卷积层的网络的版本足够精确地执行以满足我们的业务目标)。本地连接的层在每个空间位置具有128个单位,而完全连接的层每层有4096个单位。|We obtained an overall sequence transcription accuracy of 91% on this more challenging dataset. Using confidence thresholding, we were able to obtain a coverage of 83% with 99% accuracy, or 89% coverage at 98% accuracy. On this task, due to the larger amount of training data, we did not see significant overfitting like we saw in SVHN so we did not use dropout. Dropout tends to increase training time, and our largest models are already very costly to train. We also did not use maxout units. All hidden units were rectifiers (Jarrett et al., 2009; Glorot et al., 2011). Our best architecture for this dataset is similar to the best architecture for the public dataset, except we use only five convolutional layers rather than eight. (We have not tried using eight convolutional layers on this dataset; eight layers may obtain slightly better results but the version of the network with five convolutional layers performed accurately enough to meet our business objectives) The locally connected layers have 128 units per spatial location, while the fully connected layers have 4096 units per layer.
重点信息
- except we use only five convolutional layers rather than eight.
- The locally connected layers have 128 units per spatial location,
5 . 3 基于CAPTCHA拼接数据的实验
| 基于CAPTCHA拼接数据的实验 | 5.3 CAPTCHA puzzles dataset |
|---|---|
| CAPTCHA是逆向图灵测试,旨在使用扭曲的文本来区分运行自动化文本识别软件的人类和机器。reCAPTCHA是一家领先的CAPTCHA供应商,已经被应用到了数十万个网站。为了评估所提出的识别任意文本方法的一般性,我们创建了一个由最难的CAPTCHA拼图组成的数据集,如图4所示。 | CAPTCHAs are reverse turing tests designed to use distorted text to distinguish humans and ma- chines running automated text recognition software. reCAPTCHA is a leading CAPTCHA provider with an installed base of several hundreds of thousands of websites. To evaluate the generality of the proposed approach to recognizing arbitrary text, we created a dataset composed of the hardest CAPTCHA puzzle examples of which are shown in Figure 4. |
| 我们使用的模型类似于在SVHN数据集上使用的最好的模型,但有以下不同:我们在该网络中使用9个卷积层而不是11个,第一层包含正常的Relu而不是maxout,卷积层是也稍大一点,而完全连接的更小。 该模型的输出区分大小写,最多可以处理8个字符的序列。该输入是裁剪为200x40的两个CAPTCHA单词之一,其中大小为195x35的随机子作物被拍摄。下面的报告直接来自100K样本的测试集合和以数百万的CAPTCHA图像的顺序的训练集合。 | The model we use is similar to the best one used over the SVHN dataset with the following differ- ences: we use 9 convolutional layers in this network instead of 11, with the first layer containing normal rectifier units instead of maxouts, the convolutional layers are also slightly bigger, while the fully connected ones smaller. The output of this model is case-sensitive and it can handle up to 8 character long sequences. The input is one of the two CAPTCHA words cropped to a size of 200x40 where random sub-crops of size 195x35 are taken. The performance reported was taken directly from a test set of 100K samples and a training set in the order of millions of CAPTCHA images. |
重点信息
- we use 9 convolutional layers
- normal rectifier units instead of maxouts,

| 基于CAPTCHA拼接数据的实验 | 5.3 CAPTCHA puzzles dataset |
|---|---|
| 图3:从大型内部数据集中错误转录的街道数字的例子。请注意,对于其中的一些,“标签”本身也是不正确的。这个数据集中的标签相当嘈杂,这在现实世界中很常见。这个数据集中标签错误的一些原因包括:1.抄录员看到的图片不全,导致录入出错。2.一些例子基本上是模棱两可的,例如包括非数字字符的街道号码,或者在相同的图像中具有多个街道号码,人们用任意的分隔符如“,”或“。 | Figure 3: Examples of incorrectly transcribed street numbers from the large internal dataset (tran- scription vs. ground truth). Note that for some of these, the “ground truth” is also incorrect. The ground truth labels in this dataset are quite noisy, as is common in real world settings. Some reasons for the ground truth errors in this dataset include: 1. The data was repurposed from an existing in- dexing pipeline where operators manually entered street numbers they saw. It was impractical to use the same size of images as the humans saw, so heuristics were used to create smaller crops. Some- times the resulting crop omits some digits. 2. Some examples are fundamentally ambiguous, for instance street numbers including non-digit characters, or having multiple street numbers in same image which humans transcribed as a single number with an arbitrary separator like “,” or “-”. |

基于CAPTCHA拼接数据的实验 |5.3 CAPTCHA puzzles dataset |
—-|——|
图4,CPATCHA图例中的较难识别的例子|Figure 4: Examples of images from the hard CAPTCHA puzzles dataset.
基于CAPTCHA拼接数据的实验 |5.3 CAPTCHA puzzles dataset |
—-|——|
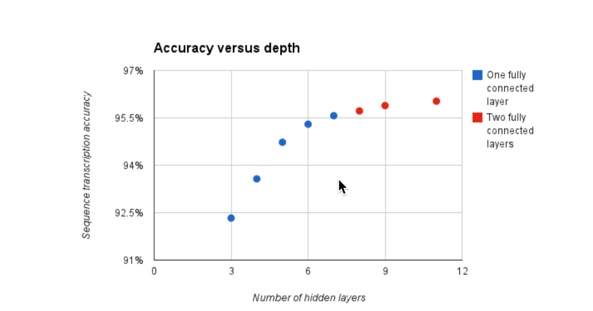
图5:公共SVHN数据集上的性能分析,实验显示,更深的网络可以带来更好的效果。|Figure 5: Performance analysis experiments on the public SVHN dataset show that fairly deep architectures are needed to obtain good performance on the sequence transcription task.
有了这个模型,我们能够在转录最困难的reCAPTCHA难题方面达到99.8%的准确率。值得注意的是,这些结果并不表示reCAPTCHA整体的防机器效果有所下降。reCAPTCHA被设计成一个风险分析引擎,从用户采取各种不同的线索来做出人与机器人的最终决定。今天,reCAPTCHA中的扭曲文本越来越多地成为捕获用户互动的媒介,而不是最初的识别人或机器。当然,这个结果表明,扭曲文本本身作为反向图灵测试的效用没有那么强。|With this model, we are able to achieve a 99.8% accuracy on transcribing the hardest reCAPTCHA puzzle. It is important to note that these results do not indicate a reduction in the anti-abuse effec- tiveness of reCAPTCHA as a whole. reCAPTCHA is designed to be a risk analysis engine taking a variety of different cues from the user to make the final determination of human vs bot. Today distorted text in reCAPTCHA serves increasingly as a medium to capture user engagements rather than a reverse turing in and of itself. These results do however indicate that the utility of distorted text as a reverse turing test by itself is significantly diminished.
5 . 4 性能/效果分析
| 性能/效果分析 | 5.4 Performance analysis |
|---|---|
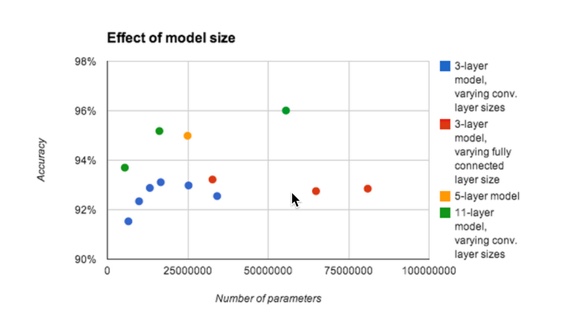
| 在本节中,我们探讨了我们的神经网络架构空前成功的原因,其中涉及到一个定位和分割的复杂任务,而不仅仅是识别。我们假设,对于这样一个复杂的任务来说,深度对于实现任务的高效表示至关重要。现有技术的识别网络对于裁剪和居中的数字或对象的图像可能具有两到四个卷积层,随后是一个或两个密集连接的隐藏层和分类层。在这项工作中,我们使用了更多的卷积层。我们假设深度对我们的成功至关重要。这很可能是因为较早的图层可以解决定位和分割任务,并且准备一个已经被分割的表示,以便后面的图层可以专注于正确的识别。此外,我们假设这样的深层网络具有很高的表现能力,因此需要大量的数据来训练。在我们成功地演示这个系统之前,预期除了深度以外的其他因素将是实现这些任务良好性能的必要条件。例如,可能有一个足够深的网络太难以优化。在图5中,我们展示了一个实验的结果,这个实验证实了我们的假设,即在这个任务中,深度对于良好的性能是必要的。对于控制实验显示大的浅层模型不能达到相同的性能,见图6。 | In this section we explore the reasons for the unprecedented success of our neural network architec- ture for a complicated task involving localization and segmentation rather than just recognition. We hypothesize that for such a complicated task, depth is crucial to achieve an efficient representation of the task. State of the art recognition networks for images of cropped and centered digits or ob- jects may have between two to four convolutional layers followed by one or two densely connected hidden layers and the classification layers (Goodfellow et al., 2013). In this work we used several more convolutional layers. We hypothesize that the depth was crucial to our success. This is most likely because the earlier layers can solve the localization and segmentation tasks, and prepare a representation that has already been segmented so that later layers can focus on just recognition. Moreover, we hypothesize that such deep networks have very high representational capacity, and thus need a large amount of data to train successfully. Prior to our successful demonstration of this system, it would have been reasonable to expect that factors other than just depth would be neces- sary to achieve good performance on these tasks. For example, it could have been possible that a sufficiently deep network would be too difficult to optimize. In Fig. 5, we present the results of an experiment that confirms our hypothesis that depth is necessary for good performance on this task. For control experiments showing that large shallow models cannot achieve the same performance, see Fig. 6. |
重点信息
- State of the art recognition networks for images of cropped and centered digits or ob- jects may have between two to four convolutional layers followed by one or two densely connected hidden layers and the classification layers
5 . 5 地理编码的应用
| 地理编码的应用 | 5.5 Application to Geocoding |
|---|---|
| 这种模式的发展动机是降低地理编码的成本,并在世界范围内扩大规模,跟上世界的变化。该模型现在已经达到了足够高的质量水平,我们可以自动提取街景图片上的街道数字。此外,即使模型可以被认为相当大,它仍然是有效的。 | The motivation for the development of this model was to decrease the cost of geocoding as well as scale it worldwide and keep up with change in the world. The model has now reached a high enough quality level that we can automate the extraction of street numbers on Street View images. Also, even if the model can be considered quite large, it is still efficient. |
| 例如,我们可以通过Google的基础设施,在不到一个小时的时间内识别所有法国街头的号码。其中大部分成本实际上来自检测阶段,即在大型街景视图图像中找到街道号码。在世界范围内,我们自动检测并转录了接近1亿个物理街道号码。拥有这个新的数据集显着提高了Google地图在几个国家的地理编码质量,特别是那些还没有其他地理编码源的国家。在图7中,您可以看到一些从南非拍摄的街景图像中自动提取的街道号码。 | We can for example transcribe all the views we have of street numbers in France in less than an hour using our Google infrastructure. Most of the cost actually comes from the detection stage that locates the street numbers in the large Street View images. Worldwide, we automatically detected and transcribed close to 100 million physical street numbers at operator level accuracy. Having this new dataset significantly increased the geocoding quality of Google Maps in several countries especially the ones that did not already have other sources of good geocoding. In Fig. 7, you can see some automatically extracted street numbers from Street View imagery captured in South Africa. |
地理编码的应用 |5.5 Application to Geocoding |
—-|——|
图6:公共SVHN数据集上的性能分析实验显示,增加较小模型中的参数数量并不能使这些模型达到与深度模型相同的性能水平。这主要是由于过度配合。|Figure 6: Performance analysis experiments on the public SVHN dataset show that increasing the number of parameters in smaller models does not allow such models to reach the same level of performance as deep models. This is primarily due to overfitting.
5 . 待讨论的问题
| 待讨论的问题 | 5 . 待讨论的问题 |
|---|---|
| 我们相信在这个模型中,我们已经解决了许多应用程序的短序列OCR。就我们的具体任务而言,我们认为现在我们可以轻易获得的最大收益是提高训练集本身的质量,并增加其通用OCR转录的规模。 | We believe with this model we have solved OCR for short sequences for many applications. On our particular task, we believe that now the biggest gain we could easily get is to increase the quality of the training set itself as well as increasing its size for general OCR transcription. |
| 我们对这种结构的一个担心是,它们严重依赖于序列是有限长度的,并且具有相当小的最大长度N的假设。对于无界N,我们的方法不是直接适用的,对于大N,我们的方法是不能很好地扩展的。每个单独的数字分类器都需要自己的单独的权重矩阵。对于长序列来说,这可能会造成太高的内存成本。使用DistBelief时,内存不是什么大问题(只要使用更多的机器),但统计效率可能会成为问题。长序列的另一个问题是成本函数本身。也有可能的是,由于较长的序列具有更多的数字概率相乘在一起,所以较长序列的模型可能在序列长度的系统性低估方面存在麻烦。 | One caveat to our results with this architecture is that they rest heavily on the assumption that the sequence is of bounded length, with a reasonably small maximum length N. For unbounded N, our method is not directly applicable, and for large N our method is unlikely to scale well. Each separate digit classifier requires its own separate weight matrix. For long sequences this could incur too high of a memory cost. When using DistBelief, memory is not much of an issue (just use more machines) but statistical efficiency is likely to become problematic. Another problem with long sequences is the cost function itself. It’s also possible that, due to longer sequences having more digit probabilities multiplied together, a model of longer sequences could have trouble with systematic underestimation of the sequence length. |
| 针对上面的问题,一种可能的解决方案是训练一个模型,一次输出一个“单词”(N个字符序列),然后在整个图像上滑动,然后进行简单的解码。 在这方面的一些早期实验是有前景的。 | One possible solution could be to train a model that outputs one “word” (N character sequence) at a time and then slide it over the entire image followed by a simple decoding. Some early experiments in this direction have been promising. |
| 或许,我们最感兴趣的发现是,神经网络可以学习执行复杂的任务,例如对象的有序序列的同时定位和分割。 这种使用单个神经网络作为整个端到端系统的方法可以适用于其他问题,如一般文本转录或语音识别。 | Perhaps our most interesting finding is that neural networks can learn to perform complicated tasks such as simultaneous localization and segmentation of ordered sequences of objects. This approach of using a single neural network as an entire end-to-end system could be applicable to other prob- lems, such as general text transcription or speech recognition. |
重点信息
- One possible solution could be to train a model that outputs one “word” (N character sequence) at a time and then slide it over the entire image followed by a simple decoding. Some early experiments in this direction have been promising.
- Perhaps our most interesting finding is that neural networks can learn to perform complicated tasks such as simultaneous localization and segmentation of ordered sequences of objects.
6 . 鸣谢,7 . 引用(略)
8 . 附录
| 示例 | Example inference | ||||
|---|---|---|---|---|---|
| 在本附录中,我们提供了一个详细的例子,说明如何在训练好的网络中来预测房屋号码。本附录的目的是消除正文中更笼统的描述中的任何含糊之处。 | In this appendix we provide a detailed example of how to run inference in a trained network to transcribe a house number. The purpose of this appendix is to remove any ambiguity from the more general description in the main text. | ||||
| 整个识别的开始,是基于给定的图像X来猜测数字的顺序S。关于如何执行该计算的细节,参见图8。 | Transcription begins by computing the distribution over the sequence S given an image X. See Fig. 8 for details of how this computation is performed. | ||||
| 为了实现一个特定的序列转录,我们需要计算argmaxs P(S = s \ | H)。在对数标度下这样做是最容易的,我们要避免将许多小数相乘,因为这样的乘法会导致数值下溢。 即我们实际上计算了argmaxs log P(S = s \ | H)。 | To commit to a single specific sequence transcription, we need to compute argmaxs P (S = s \ | H). It is easiest to do this in log scale, to avoid multiplying together many small numbers, since such multiplication can result in numerical underflow. i.e., in practice we actually compute argmaxs log P (S = s \ | H). |
| 请注意,log softmax(z)可以通过公式log softmax(z)i = zi - Sigma(j exp(zj))有效地计算并具有数值稳定性。最好使用这种稳定的方法计算对数概率,而不是首先计算概率,然后取对数。后一种方法是不稳定的; 对于小概率,它可以错误地产生负无穷。 | Note that log softmax(z) can be computed efficiently and with numerical stability with the formula log softmax(z)i = zi - Sigma( j exp(zj )). It is best to compute the log probabilities using this stable approach, rather than first computing the probabilities and then taking their logarithm. The latter approach is unstable; it can incorrectly yield - infinite for small probabilities. | ||||
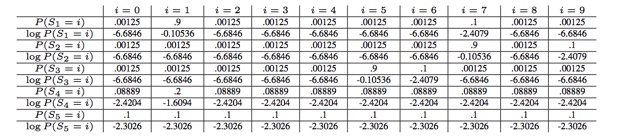
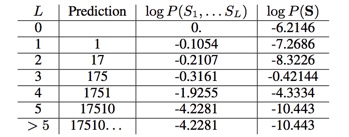
| 假设我们已经计算了所有输出概率,并且它们是以下(这些是理想化的示例值,而不是来自模型的实际值): | Suppose that we have all of our output probabilities computed, and that they are the following (these are idealized example values, not actual values from the model): |
| 示例 | L=0 | L=1 | L=2 | L=3 | L=4 | L=5 | L>5 |
|---|---|---|---|---|---|---|---|
| P (L) | .002 | .002 | .002 | .9 | .09 | .002 | .02 |
| logP(L) | -6.2146 | -6.2146 | -6.2146 | -0.10536 | -2.4079 | -6.2146 | -6.2146 |
| 示例 | Example inference |
|---|---|
| 参考图8中的示例输入图像来理解这些概率。正确的长度是3.我们在L上的分布准确地反映了这一点,虽然我们认为有一个合理的可能性,L是4,也许门的边缘看起来像一个第四位数字。正确的转录是175,我们确实给这些数字赋予了最高的概率,但是也给第一个数字赋予了一个7的概率,第二个是9,或者第三个是6.没有第四个数字,但是如果我们把门的边缘解释为一个数字(这有一定的可能性),因为没有第五个数字,我们在第五个数字上的分布是完全统一的。 | Refer to the example input image in Fig. 8 to understand these probabilities. The correct length is 3. Our distribution over L accurately reflects this, though we do think there is a reasonable possibility that L is 4– maybe the edge of the door looks like a fourth digit. The correct transcription is 175, and we do assign these digits the highest probability, but also assign significant probability to the first digit being a 7, the second being a 9, or the third being a 6. There is no fourth digit, but if we parse the edge of the door as being a digit, there is some chance of it being a 1. Our distribution over the fifth digit is totally uniform since there is no fifth digit. |
| 我们的独立性假设意味着,当我们计算最可能的序列时,选择哪个数字出现在每个位置并不影响我们选择哪个数字出现在其他位置。因此,我们可以分别在每个位置选择最可能的数字,留给我们这个表格: | Our independence assumptions mean that when we compute the most likely sequence, the choice of which digit appears in each position doesn’t affect our choice of which digit appears in the other positions. We can thus pick the most likely digit in each position separately, leaving us with this table: |

| 示例 | Example inference |
|---|---|
| 最后,我们可以通过明确计算所有七个可能的序列长度的概率来完成最大化: | Finally, we can complete the maximization by explicitly calculating the probability of all seven possible se- quence lengths: |
| 示例 | Example inference |
|---|---|
| 这里第三列只是log P(SL)的累计和,所以可以用线性时间来计算。同样,第四列是通过将第三列添加到我们现有的日志P(L)表中计算出来的。甚至没有必要在内存中保留这个最终表,我们可以使用一个for循环,每次生成一个元素并记住最大元素。 | Here the third column is just a cumulative sum over log P (SL ) so it can be computed in linear time. Likewise, the fourth column is just computed by adding the third column to our existing log P (L) table. It is not even necessary to keep this final table in memory, we can just use a for loop that generates it one element at a time and remembers the maximal element. |
| 正确的转录175获得0.42144的最大对数概率,并且模型输出这个正确的转录。 | The correct transcription, 175, obtains the maximal log probability of 0.42144, and the model outputs this correct transcription. |

示例 |Example inference |
—-|——|
图7:从南非拍摄的Street View图像中自动提取的街道号码。|Figure 7: Automatically extracted street numbers from Street View imagery captured in South Africa.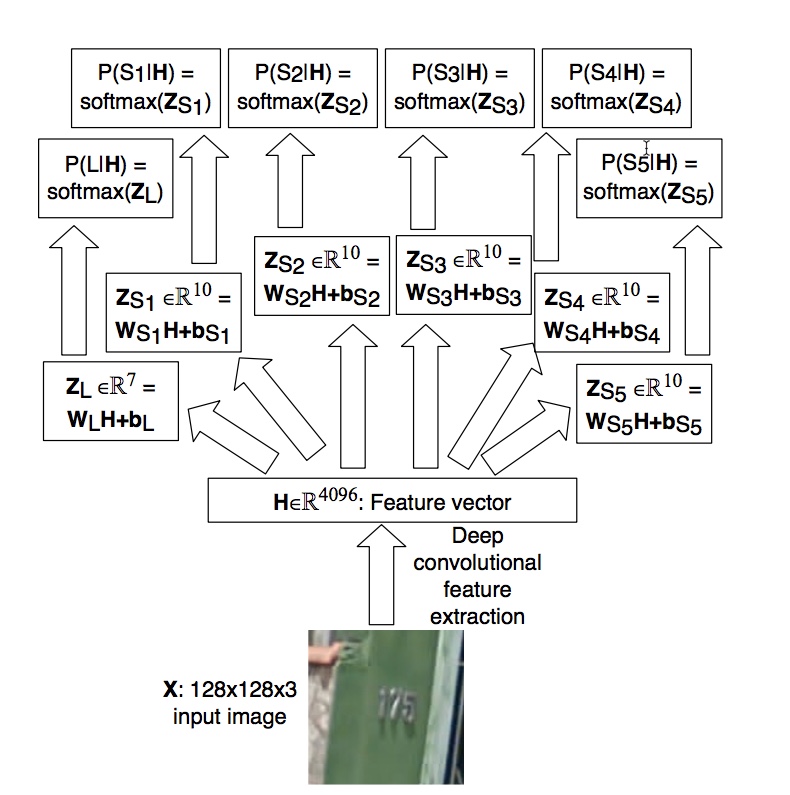
示例 |Example inference |
—-|——|
图8:我们用来识别房屋号码的模型架构图。在这个图中,我们展示了如何计算P(S | X)的参数,其中X是输入图像,S是图像描述的数字序列。我们首先使用具有完全连接的最终层的卷积网络从X中提取一组特征H.注意,只有一个这样的特征向量被提取用于整个图像。我们不使用HMM来模拟在不同位置明确提取的特征。因为卷积特征提取器的最后一层是完全连接的,没有共享权重分配,所以我们没有明确地将任何空间位置的概念设计到这个表示中。网络必须学习它自己的表示空间位置的方法。然后将六个独立的softmax分类器连接到这个特征向量H上,即每个softmax分类器通过对H进行仿射变换并用softmax函数对这个响应进行归一化来形成一个响应。其中一个分类器提供了序列长度P(L | H)上的分布,而其他分布器则提供了序列中每个成员的分布P(S1 \ H),…,P | H)。|Figure 8: Details of the computational graph we used to transcribe house numbers. In this diagram, we show how we compute the parameters of P (S | X), where X is the input image and S is the sequence of numbers depicted by the image. We first extract a set of features H from X using a convolutional network with a fully connected final layer. Note that only one such feature vector is extracted for the entire image. We do not use an HMM that models features explicitly extracted at separate locations. Because the final layer of the convolutional feature extractor is fully connected and has no weight sharing, we have not explicitly engineered any concept of spatial location into this representation. The network must learn its own means of representing spatial location in H. Six separate softmax classifiers are then connected to this feature vector H, i.e., each softmax classifier forms a response by making an affine transformation of H and normalizing this response with the softmax function. One of these classifiers provides the distribution over the sequence length P (L | H), while the others provide the distribution over each of the members of the sequence, P(S1 | H),…,P(S5 | H).
重点信息
- how we compute the parameters of P (S | X), where X is the input image and S is the sequence of numbers depicted by the image.
- Because the final layer of the convolutional feature extractor is fully connected and has no weight sharing, we have not explicitly engineered any concept of spatial location into this representation. The network must learn its own means of representing spatial location in H. Six separate softmax classifiers are then connected to this feature vector H